Introduction
Built with sNyung
JavaScript란?
JavaScript(JS)는 가벼운 인터프리터형, JIT-컴파일형 프로그래밍 언어, first-class functions를 지원한다.
주로 웹 페이지를 위한 스크립팅 언어로 알려졌지만, Node.js, Apache CouchDB, Adobe Acrobat처럼 많은 비 브라우저 환경에서도 사용된다.
JavaScript는 프로토타입 기반의 다중 패러다임 스크립팅 언어로서, 역동적이고, 객체지향형, 명령형 및 선언형(가령 함수형 프로그래밍) 스타일을 지원한다.
이 문서는 JavaScript 언어 자체만 다루며 웹 페이지를 비롯한 다른 사용 환경에 대해서는 다루지 않는다. 웹 페이지의 특정 API에 대하여 알고 싶다면 웹 API와 DOM을 참고하면 됩니다.
JavaScript의 표준은 ECMAScript입니다.
2012년 기준 최신 브라우저는 모두 ECMAScript 5.1을 전부 지원한다.
이전 브라우저의 경우는 최소한 ECMAScript 3까지 지원한다.
2015년 6월 17일 ECMA International에서는 ㄴ공식명 ECMAScript 2015로 불리는 ECMAScript의 6번째 주 버전을 발표했다(ECMAScript 6 혹은 ES6).
그 이후 ECMAScript 표준은 출시가 1년 주기이다.
JavaScript를 Java 프로그래밍 언어와 혼동해서는 안된다.
"Java"와 "JavaScript" 두 가지 모두 Oracle이 미국 및 기타 국가에 등록한 상표이다. 하지만, 두 언어는 문법 체계와 사용방법이 전혀 다릅니다.
Reference
Call Stack
Intro
지금 이 글을 보고 있는 우리가 공부할 언어는 Script 언어로 이름은 자바스크립트다.
공부할 언어가 어떤 것이 어떻게 실행되는지 알아보기 위해서는 엔진에 대해서 알아야 한다고 생각한다.
V8 Engine
가장 많이 사용되는 브라우저는 Chrome이다. 이 Chrome에서 사용되는 자바스크립트 엔진은 구글의 V8 Engine이다.
V8 Engine에는 2가지 Main Components가 있다.
- Memory Heap : 메모리의 할당이 일어나는 곳.
- Call Stack : Stack Frame이 실행되는 곳. 쉽게 말해서 우리가 작성한 코드가 실행되는 곳.
Call Stack
Call Stack은 LIFO (Last In, First Out) 원리를 사용하여 함수 호출을 임시 저장하고 관리하는 데이터 구조.
LIFO : Last In, First Out의 데이터 구조 원칙에 따라 Call Stack이 작동한다. Stack으로 push된 마지막 함수가 처음으로 나옴을 의미한다.
자바스크립트에서 Call Stack은 주로 함수 호출에 이용된다. Call Stack이 하나이기 때문에 함수 실행은 위에서 아래로 한 번에 하나씩 수행된다.
기본적으로 자바스크립트는 싱글 스레드 프로그래밍 언어이다. 이 말은 하나의 Call Stack을 가지고 있다는 것을 의미한다. 다른 말로 하자면 한 번에 한 가지 일만 할 수 있다는 것이다.
function multiply(x, y) {
return x * y;
}
function printSquare(x) {
const s = multiply(x, x);
console.log(s);
}
printSquare(5);
위와 같은 코드가 있다면,
printSquare(5) ⇒ multiply(x, x) ⇒ console.log(s) ⇒ printSquare(5)
순서로 쌓이고 실행이 된다는 것을 의미한다.
각 한 줄을
Stack Frame이라고 한다.
function foo() {
throw new Error('Session Stack will help you resolve crashes :)');
}
function bar() {
foo();
}
function start() {
bar();
}
start();
위와 같은 코드를 Chrome에서 실행한다면 당연하게 에러가 나면서 Stack 형태를 자세히 볼 수 있다.
다른 경우로는 Call Stack의 사이즈를 넘어서 쌓이는 경우도 발생한다.
let i = 0;
function recurse () {
i++;
recurse();
}
try {
recurse();
} catch (e) {
alert('maxStackSize = ' + i + '\nerror: ' + e);
}
위의 코드를 사용하면 안되지만 위의 같은 경우는 브라우저에서 계속 쌓아가다가 크롬 기준 약 15,000개가 넘어가는 순간에 Stack Size가 넘쳤다고 나올 것이다.

당연하겠지만 엔진이 다르면 최대치가 다르다.
싱글 스레드는 멀티 스레드보다 다루기는 쉽다.
Deadlock(교착상태) 같은 일이 발생하지 않는다.
그러나 역시 제한적이다. 예시로 내가 버튼을 눌러서 서버에서 사진을 가져오려고 할 때. 버튼을 누르고 사진을 가져올 때까지 브라우저는 멈춘 상태가 되어 버린다.
이에 대안으로 Asynchronous Callbacks 이다.
Web API
자바스크립트에 제공되지 않는 것들이 있다. 우리가 비동기를 사용하기 위해서 사용하는 setTimeOut(), setInterval()와 같은 기능들이 브라우저에서 제공하는 API라고 생각하면 된다.
지원하는 API는,
- DOM Event
- AJAX(=XMLHttpRequest)
- setTimeOut
- 이외
브라우저 웹 API : DOM 이벤트,
XMLHttpRequest,setTimeout과 같은 비동기 이벤트를 처리하기 위해 C++로 구현된 브라우저로 만든 스레드
Queue(Message Queue || CallBack Queue)
자바스크립트 런타임에는 처리할 메시지 목록과 콜백 함수인 Message Queue가 있다. 현재 Stack의 용량이 충분하다면 Queue에서 메시지를 가져와서 처리된 CallBack function을 실행한다.
기본적으로 이러한 메시지는 콜백 기능이 제공되면 외부 비동기 이벤트에 대해 응답을 한다. 예를 들어 사용자가 버튼을 클릭하고 콜백 함수가 제공되지 않으면 아무런 메시지도 Queue에 추가되지 않게 되는 것이다.
Event Loop
네크워크는 느리다. 사진을 불러오는 것이 느린 이유이다. 이에 흔히 사용되는 것이 AJAX라 불리는 비동기 함수다. 만약 이러한 작업이 동기라면 사진을 불러오는 동안 화면이 멈추는 현상이 일어날 것이다.
가장 쉬운 해결책이 Asynchronous Callbacks이다.
console.log()와 다르게 바로 실행되지 않는다. 그렇다면 이런 어떻게 되는가?
응답에서 호출자를 분리하면 비동기 작업이 완료되고 콜백이 시작될 때까지 기다리는 시간 동안 자바스크립트 런타임에서는 다른 작업을 할 수 있다.
Web API에서 요청한 작업을 완료한 후 Callbacks을 실행해야 한다. 그러나 만약 작업이 완료되고 직접 Web API 쪽에서 Call Stack에 실행 코드를 넣을 수 있다면 끝나는 즉시 Call function이 실행될 것이다.
그래서 있는 것이 Queue다. Web API에서 요청한 작업을 완료한 후에 Queue에 넣어 준다.
Event Loop는 Call Stack이 비었을 때를 파악하여 Queue에서 들어온 Callback function를 순서에 맞게 수행한다.
Execute Context
실행 컨텍스트는 자바스크립트 코드가 평가되고 실행되는 환경의 추상적인 개념이다. 자바스크립트에서 코드를 실행할 때마다 실행 컨텍스트 내에서 실행된다.
자바스크립트 내에는 3가지 타입의 실행컨텍스트가 있다고 한다.
- Global
- Functional
Eval Function
중요한 것은 1번, 2번이다.
Execution Stack
실행 스택은 위에서 보았다. Call Stack의 개념이다. 실행컨텍스트를 만드는 두 단계가 있다.
- Creation 단계
- Execute 단계
Creation 단계
한국말로는 만드는 단계이다. 두 가지를 만든다.
- LexicalEnvironment
- VariableEnvironment
기본 형태는 아래와 같다.
ExecutionContext = {
LexicalEnvironment = <ref. to LexicalEnvironment in memory>,
VariableEnvironment = <ref. to VariableEnvironment in memory>,
}
Lexical Environment
Lexical Environment은 식별자, 변수 맵핑을 가지고 있는 구조다.
여기서 식별자는 변수/함수의 이름을 가리키며 변수는 실제 객체 [함수 객체 및 배열 객체 포함] 대한 참조입니다.
var a = 20;
var b = 40;
function foo() {
console.log('bar');
}
위와 같은 코드가 있다고 하면 Lexical Environment은
lexicalEnvironment = {
a: 20,
b: 40,
foo: <ref. to foo function>
}
위와 같이 만들어질 것이다.
여기에는 3가지의 정보를 가지고 있다.
- Environment Record : 변수 및 함수 선언이 Lexical Environment 내에 저장되는 장소
- Reference to the outer environment : 외부 환경에 대한 참조
- This binding :
this가 결정되거나 설정된다.
Environment Record
기본적으로 2가지 정보를 담고 있다.
- Declarative environment record (선언적 환경 정보) : 변수 및 함수 선언을 저장합니다.
- Object environment record (객체 환경 정보) : 전역 코드의 Lexical Environment에는 객체 환경 레코드가 포함되어 있다. 변수 및 함수 선언 외에 객체 환경 레코드는 전역 바인딩 객체 (브라우저의 창 개체)도 저장합니다. 따라서 각 바인딩 객체의 속성에 대해 새 항목이 레코드에 만들어진다.
함수 코드의 경우 Environment Record에는 함수에 전달된 인덱스와 인수 사이의 매핑과 함수에 전달된 인수의 길이가 포함된 arguments 객체도 포함이 된다.
예를 들어, 아래 함수에 대한 인수 객체는 다음과 같다.
function foo(a, b) {
var c = a + b;
}
foo(2, 3);
// argument object
Arguments: {0: 2, 1: 3, length: 2},
Reference to the Outer Environment
외부 환경에 대한 참조는 outer environment에 액세스 할 수 있음을 의미한다. 즉, 자바스크립트 엔진은 현재 lexical environment에서 찾을 수 없는 경우 outer environment에서 변수를 찾을 수 있다.
This Binding
여기에는 어렵고도 중요한 개념인 this가 결정되거나 설정된다.
전역 실행 컨텍스트에서이 값은 전역 개체를 참조합니다.
함수 실행 컨텍스트에서이 값은 함수가 호출되는 방식에 따라 다르게 this가 나온다. 객체 참조 때문에 호출되면 this 값은 해당 객체로 설정되고, 그렇지 않으면 이 값은 전역 객체로 설정되거나 정의되지 않는다.
const person = {
name: 'peter',
birthYear: 1994,
calcAge: function() {
console.log(2018 - this.birthYear);
}
}
person.calcAge();
// 'this' refers to 'person', because 'calcAge' was called with //'person' object reference
const calculateAge = person.calcAge;
calculateAge();
// 'this' refers to the global window object, because no object reference was given
Variable Environment
이것은 위에서 봤던 LexicalEnvironment와 같다.
ES6에서 LexicalEnvironment 구성 요소와 VariableEnvironment 구성 요소의 차이점 중 하나는 함수 선언과 변수 (let 및 const)바인딩을 저장하는데 사용되는 반면, 후자는 변수 (var)바인딩만 저장하는 데 사용된다.
Execute 단계
이 단계에서 모든 변수에 대한 할당이 완료되고 코드가 최종적으로 실행된다.
let a = 20;
const b = 30;
var c;
function multiply(e, f) {
var g = 20;
return e * f * g;
}
c = multiply(20, 30);
GlobalExectionContext = {
LexicalEnvironment: {
EnvironmentRecord: {
Type: "Object",
// Identifier bindings go here
a: < uninitialized >,
b: < uninitialized >,
multiply: < func >
}
outer: <null>,
ThisBinding: <Global Object>
},
VariableEnvironment: {
EnvironmentRecord: {
Type: "Object",
// Identifier bindings go here
c: undefined,
}
outer: <null>,
ThisBinding: <Global Object>
}
}
GlobalExectionContext = {
LexicalEnvironment: {
EnvironmentRecord: {
Type: "Object",
// Identifier bindings go here
a: 20,
b: 30,
multiply: < func >
}
outer: <null>,
ThisBinding: <Global Object>
},
VariableEnvironment: {
EnvironmentRecord: {
Type: "Object",
// Identifier bindings go here
c: undefined,
}
outer: <null>,
ThisBinding: <Global Object>
}
}
FunctionExectionContext = {
LexicalEnvironment: {
EnvironmentRecord: {
Type: "Declarative",
// Identifier bindings go here
Arguments: {0: 20, 1: 30, length: 2},
},
outer: <GlobalLexicalEnvironment>,
ThisBinding: <Global Object or undefined>,
},
VariableEnvironment: {
EnvironmentRecord: {
Type: "Declarative",
// Identifier bindings go here
g: undefined
},
outer: <GlobalLexicalEnvironment>,
ThisBinding: <Global Object or undefined>
}
}
FunctionExectionContext = {
LexicalEnvironment: {
EnvironmentRecord: {
Type: "Declarative",
// Identifier bindings go here
Arguments: {0: 20, 1: 30, length: 2},
},
outer: <GlobalLexicalEnvironment>,
ThisBinding: <Global Object or undefined>,
},
VariableEnvironment: {
EnvironmentRecord: {
Type: "Declarative",
// Identifier bindings go here
g: 20
},
outer: <GlobalLexicalEnvironment>,
ThisBinding: <Global Object or undefined>
}
}
함수 실행이 완료된 후 반환 값은 c 안에 저장된다. 그래서 글로벌 Variable Environment에 업데이트된다. 그 후, 전역 코드가 완료되고 프로그램이 완료된다.
let 및 const 정의 변수는 생성 단계에서 연관된 값이 없지만 var 정의 변수는 undefined로 설정된다.
이는 생성 단계에서 함수 선언이 환경에 전체적으로 저장되는 동안 변수 및 함수 선언에 대해 코드가 검색되고 변수가 초기에 undefined(var의 경우)로 설정되거나 초기화되지 않은 상태로 유지되기 때문이다. let과 const의 경우).
var 정의 변수가 선언되기 전에 (정의되지는 않았지만) var 정의 변수에 액세스 할 수 있지만 let 및 const 변수가 선언되기 전에 액세스 할 때 참조 오류가 발생하는 이유다.
실행 단계에서 자바스크립트 엔진이 let 변수의 값을 소스 코드에서 선언된 실제 위치에서 찾지 못하면 정의되지 않은 값을 할당한다.
Type
Primitive Type(원시 타입)
간단하게 말하면 원시 자료형이라고 하는 Javascript의 타입에 대해서 알아보자.
Javascript는 자바나 C언어와는 다르게 동적 타입 언어라 불린다. 동적 타입 언어의 자료형은 컴파일 시 자료형을 정하는 것이 아니고 실행 시에 결정된다.
Javascript의 타입 종류와 사용법에 대해서 알아보자.
6가지의 기본 Type
ES6 이전에는 5가지의 타입이었으나, ES6에서 Symbol 타입이 추가되어 총 6가지가 되었다.
- String : 텍스트를 설정할 때 사용하는 타입이다..
- Number : 숫자를 설정할 때 사용하는 타입이다. 소수점도 표현도 가능하다(
infinity,-inifinity,NaN표현이 가능하다.). - Null : null 타입은 정확히는 1개의 값은 가지고 있지만, 비어있다는 뜻이다.
- Undefined : 값이 할당되지 않은 것을 나타내는 타입이다.
- Boolean :
true또는false로 나타내는 타입이다. - Symbol : 새로 추가된 타입으로 unique하고 immutable한 원시값 으로 사용된다.
위에서 보이듯이 기본적으로 6가지의 형태를 가지고 있으며, 나머지는 Object형이라고 통칭한다.
- Array : 배열, 리스트의 형태를 가지고 있다.
- Function : Javascript에서 Function Object가 존재하지만 결국, Function도 Object이다.
- Object : Map처럼 사용하는 즉, key : value의 형태로 사용하고 있는 Object.
위에서 보았던 6가지 기본타입을 생성하는 방법은 크게 2가지이다.
- Literal로 생성하기
Literal로 생성한다고 하면 우리가 가장 많이 사용하는 방법이다. 단순하게 변수를 초기화 후 할당하는 방법과 초기화를 하고 나중에 할당하는 방법으로 구분을 지을 수 있다.
// 초기화와 할당을 동시에 진행
var bol = true;
var str = "hello";
var num = 3.14;
var nullType = null;
var undef = undefined;
// 초기화 후 할당진행
var bol2;
var str2;
bo2 = false
str2 = "world"
- Wrapper Object를 사용해서 만들기
Wrapper Object를 사용해서 만든다고 하면 Constructor를 사용해서 만드는 것을 말한다. 쉽게 말하자면 new를 사용해서 만드는 것이다.
new Boolean(false);
new String("world");
new Number(42);
Symbol("foo"); //Symbol 타입의 생성방법
Literal로 생성하는 방법과 Wrapper Object를 사용해서 만드는 방법은 차이점이 있다.
typeof true; //"boolean"
typeof Boolean(true); //"boolean"
typeof new Boolean(true); //"object"
typeof (new Boolean(true)).valueOf(); //"boolean"
typeof "abc"; //"string"
typeof String("abc"); //"string"
typeof new String("abc"); //"object"
typeof (new String("abc")).valueOf(); //"string"
typeof 123; //"number"
typeof Number(123); //"number"
typeof new Number(123); //"object"
typeof (new Number(123)).valueOf(); //"number"
중간중간 new를 사용하지 않은 것은 window.Boolean, window.String와 같은 형식으로 생각하면 되며, 이러한 Function은 해당 타입으로 변환하는 작업할 때 사용된다.
위에서 보게 되면 Literal로 생성한 것의 타입은 6가지 중 하나로 나오게 된다. 그런데 new를 사용하여 Wrapper Object로 만들게 되면 Object타입이 나오게 된다. 사용하려면 valueOf라는 Function을 사용해야만 입력한 값이 나오게 된다.
아래의 예제를 보자. 어떻게 결과가 어떻게 6이 나올 수 있는 것인가?
var str = 'string'
str.length // 6
위의 예제는 단순하게 str 변수 안에 'string'이라는 String 타입의 값을 할당했다. 그런데 해당 변수는 Wrapper 객체가 아닌데 어떻게 개수를 세는 Method를 사용하고 있는 것인가?
String.prototype.returnMe= function() {
return this;
}
var a = "abc";
var b = a.returnMe();
a; //"abc"
typeof a; //"string" (still a primitive)
b; //"abc"
typeof b; //"object"
위의 예제를 보게 되면 답이 나오게 된다. 우리가 사용하는 var str를 사용하게 되면 Wrapper 객체로 임시변환이 이루어지고 returnMe() 와 같은 함수를 사용하면 다시 Wrapper 객체가 사라지게 된다.
심화 내용
Javascript에서는 신기하게 숫자 타입을 하나로 사용하고 있다. 어떻게 하나의 타입으로 모든 것을 표현할 수 있는 것일까? Number타입은 국제 표준 부동 소수점 IEEE 754를 따르고 있다. 기본적으로 컴퓨터가 실수를 표현하는 방식은 2진법인 것을 따라
13 = 8 + 4 + 1이므로 해당 자리 숫자를 1로 표현하고 나머지는 0으로 표현하게 되고 1101이 된다.0.75 = 0.5 + 0.25이므로 0.11로 표현할 수 있다.
일반적으로 소수점을 표현하는 방법은 2가지 방법이 있다.
고정 소수점
- 정수를 표현하는 비트 수와 소수를 표현하는 비트 수를 미리 정해놓고 해당 비트만큼 사용해서 숫자를 표현하는 방식.
- 예) 실수 표현에 4byte(32bit)를 사용하고 그 중 부호 1bit, 정수 16bit, 소수 15bit 를 사용하도록 약속해 놓은 시스템에 있다. 이렇게 약속된 시스템에서 263.3을 표현하면 (0)0000000100000111.010011001100110 이렇게 표현된다.
- 정수를 표현하는 비트 수를 늘리면 큰 숫자를 표현할 수 있지만 정밀한 숫자를 표현하긴 힘들다. 그래서 소수를 표현하는 bit를 늘리면 정밀한 숫자를 표현할 수 있지만 큰 숫자를 표현하지 못한다.
이런 문제를 해결하기 위해서 소수점을 고정하지 않고 표현할 수 있는 부동 소수점(floating point) 을 사용하게 되었다.
부동소수점
부동 소수점을 표현하는 방식도 정하는 방식에 따라 다를 수 있지만, 일반적으로 사용하고 있는 방식은 위에서 언급한 IEEE 754에서 표준으로 제안한 방식을 따른다.
우선 고정 소수점으로 나타낸 263.3을 2진수 부동 소수점 방식으로 변환을 해보면, 100000111.010011001100110... 으로 표현되던 것을 맨 앞에 있는 1 바로 뒤로 소수점을 옮겨서 표현하도록 변환하게 되면 1.00000111010011001100110... * 2^8(2의 8승) 으로 표현된다.
- 2^8의 8을 지수라고 하고 지수 부분에 기록하고(IEEE 754 표현 방식에서는 127 + 지수를 기록한다. )
- 소수점 이후 숫자열 전체를 가수라고 하고 가수 부분에 기록한다.
최종적인 모양을 아래와 같다.
- 부호 비트(1 bit) : 0 (양수)
- 지수 비트(8 bit) : 10000111 (127 + 8 = 135)
- 가수 비트(23 bit) : 00000111010011001100110
이렇게 표현하게 된다.
하지만 여기서도 0.010011001100110은 정확히 0.3을 나타낼 수 없게 된다. 10진수로 나타내 보면 0.29998779296875로 나오게 된다. 그래서 Javascript에서 0.1 + 0.2를 하게 되면 0.30000000000000004가 나오는 이유이다.
블록체인에서는 부동소수점에서 8자리까지를 사용한다고 한다.
값 타입과 참조 타입
기본적으로 원시 타입을 값 타입이라고 한다면 Object를 참조 타입이다.
원시 타입은 값타입이다.
var a = 13 // assign `13` to `a`
var b = a // copy the value of `a` to `b`
b = 37 // assign `37` to `b`
console.log(a) // => 13
위에서 b에 a의 값을 복사했다. 그리고 b의 값을 변경했는데 a에는 영향이 가지 않았다. 이유는 당연하게 2개의 값이 저장된 공간이 다르기 때문이다.
var a = 5;
var b = a;
a = 10;
console.log(a); // 10
console.log(b); // 5
// string, boolean, null, undefined은 같은 결과가 나온다.
Object는 참조타입이다.
var a = { c: 13 } // assign the reference of a new object to `a`
var b = a // copy the reference of the object inside `a` to new variable `b`
b.c = 37 // modify the contents of the object `b` refers to
console.log(a) // => { c: 37 }
원시 타입과는 다르게 복사한 것을 변경했더니 a에도 영향이 간다. 이유는 당연하게 같은 값의 주소를 복사하여 a에 들어있는 주소의 공간이 바뀌었으므로 a로 바뀐 값을 불러오는 것이다.
var a = {};
var b = a;
a.a = 1;
console.log(a); // {a: 1}
console.log(b); // {a: 1}
array의 경우에 있어도 예외는 없다.
var a = [];
var b = a;
a.push(1);
console.log(a); // [1]
console.log(b); // [1]
console.log(a === b); // true
function changeAgeImpure(person) {
person.age = 25;
return person;
}
var alex = {
name: 'Alex',
age: 30
};
var changedAlex = changeAgeImpure(alex);
console.log(alex); // -> { name: 'Alex', age: 25 }
console.log(changedAlex); // -> { name: 'Alex', age: 25 }
function changeAgePure(person) {
var newPersonObj = JSON.parse(JSON.stringify(person));
newPersonObj.age = 25;
return newPersonObj;
}
var alex = {
name: 'Alex',
age: 30
};
var alexChanged = changeAgePure(alex);
console.log(alex); // -> { name: 'Alex', age: 30 }
console.log(alexChanged); // -> { name: 'Alex', age: 25 }
문제
function changeAgeAndReference(person) {
person.age = 25;
person = {
name: 'John',
age: 50
};
return person;
}
var personObj1 = {
name: 'Alex',
age: 30
};
var personObj2 = changeAgeAndReference(personObj1);
console.log(personObj1); // -> ?
console.log(personObj2); // -> ?
답
👉 답 확인하기
명시적 변환, 암시적 변환, 덕 타이핑
명시적 변환 vs 암묵적 변환
개발자가 Number(value)와 같은 코드를 작성하여 변환할 의사를 명확하게 표현하는 것을 명시적 변환이라고 한다. JavaScript는 약타입 언어이므로 값을 자동으로 여러 유형간에 변환을 자동으로 한다. 이것을 암묵적 변환 이라고 한다.
예를 들어 일반적으로 연산자를 다양한 유형의 값에 적용하면 1 == null, 2 / '5', null + new Date () 또는 if (value) {...} 와 같이 문법에 의해 발생할 수 있다.
우리가 가장 많이 사용하는 암시적 타입 변환을 하지 않는 연산자는 === 이며, 완전 항등 연산자 라고 한다. 반면에 느슨한 항등 연산자 == 는 필요하다면 비교와 타입 강제 변환을 수행한다.
암시적 타입 변환으로 == 을 사용하게 되면, 가독성을 잃지 않으면서 적은 코드로 작성할 수있는 유용한 매커니즘이다. 그러나 ES6+를 사용한다면 느슨한 항등 연산자는 사용하지 않는 것을 추천한다. 완전하게 항등연산자를 이해하고 결괏값을 예상할 수 있는 경우가 아니라면 내가 생각한 것과 다른 결과가 나올 확률이 매우 높다.
기본적으로 변환은 3가지 유형의 전환이 있다.
- to string
- to boolean
- to number
String 변환
명시적으로 값을 문자열로 변환하려면 String() 함수를 사용하면 된다. 암시적 강제 변환은 binary 연산자가 아닌 것에 + 연산자를 사용하면 변환이 이루어진다.
String(123) // 명시적
123 + '' // 암시적
아래의 예제를 보면 예상대로 다 문자열로 변환이 잘 이루어지고 있다.
String(123) // '123'
String(-12.3) // '-12.3'
String(null) // 'null'
String(undefined) // 'undefined'
String(true) // 'true'
String(false) // 'false'
Symbol은 생각과 다르게 나온다.
String(Symbol('my symbol')) // 'Symbol(my symbol)'
'' + Symbol('my symbol') // TypeError is thrown
Symbol 변환은 명시적으로만 변환될 수 있고, 암시적 변환은 되지 않는다.
Boolean 변환
명시적으로 값을 Boolean으로 변환하려면 Boolean() 함수을 사용하면 된다. 암시적 변환은 논리 Context에서 발생하거나 논리 연산자에 의해 작동을 하게 된다.( ||, &&, ! )
Boolean(2) // 명시적
if (2) { ... } // 논리적 문맥 때문에 암시적
!!2 // 논리적 문맥 때문에 암시적
2 || 'hello' // 논리적 문맥 때문에 암시적
논리 연산자(예 : || 및 && )에 따른 Boolean 변환을 내부적으로 수행하지만 Boolean값이 아니더라도 원래 피연산자의 값을 실제로 반환한다. 아래를 보게 되면 Boolean 변환을 해서 검사는 하지만 실제로는 123도 반환되고 있다.
// true를 반환하는 것이 아닌 123를 반환하고 있다.
// 'hello' and 123 은 표현식을 계산하기 위해서 Boolean으로 강제 변환을 한다.
let x = 'hello' && 123; // x === 123
Boolean 변환의 결과는 true, false 2개만 있다. false 값 목록은 쉽게 기억이 가능하다.
Boolean('') // false
Boolean(0) // false
Boolean(-0) // false
Boolean(NaN) // false
Boolean(null) // false
Boolean(undefined) // false
Boolean(false) // false
목록에 없는 값 object, function, Array, Date, 사용자 정의 유형등은 true 로 변환한다.
Boolean({}) // true
Boolean([]) // true
Boolean(Symbol()) // true
!!Symbol() // true
Boolean(function() {}) // true
Numeric 변환
명시적 변환의 경우 Boolean() 및 String() 에서와 마찬가지로 Number() 함수를 사용하면 된다. 암시적 변환은 많은 경우에서 작동이 되기 때문에 까다롭다.
- 비교 연산자(
>,<,<=,>=) - 비트 연산자(
|&^~) - 산수 연산자 (
-+*/%).- 참고로,
+는 피연산자가 문자열일 때 숫자 변환을 하지 않고 문자열 변환을 한다.
- 참고로,
- 단항 연산자(기호로 사용하는)
+ - 느슨한 비교 연산자
==(!=).- 두 피연산자가 모두 문자열 인 경우
==는 숫자 변환을 하지 않는다.
- 두 피연산자가 모두 문자열 인 경우
Number('123') // 명시적
+'123' // 암시적
123 != '456' // 암시적
4 > '5' // 암시적
5 / null // 암시적
true | 0 // 암시적
Number(null) // 0
Number(undefined) // NaN
Number(true) // 1
Number(false) // 0
Number(" 12 ") // 12
Number("-12.34") // -12.34
Number("\n") // 0
Number(" 12s ") // NaN
Number(123) // 123
문자열을 숫자로 변환할 때 엔진은 먼저 앞뒤의 공백, \ n, \ t 문자를 제거하고, 문자열이 유효한 숫자를 나타내지 않으면 NaN 을 반환한다. string이 비어 있으면 0을 반환합니다.
null와 undefined는 다르게 처리가 되는데 null은 0으로 undefined는 NaN으로 된다.
Symbol은 명시적 또는 암시적으로 숫자로 변환될 수 없다. 또한 TypeError는 undefined로 발생하는 것처럼 NaN으로 자동 변환하는 대신 throw 된다.
Number(Symbol('my symbol')) // TypeError is thrown
+Symbol('123') // TypeError is thrown
기억해야 할 두 가지 특별한 규칙이 있는데
==를null또는undefined에 적용하면 숫자 변환이 발생하지 않는다.null는null,undefined과 동일하다.
null == 0 // false, null is not converted to 0
null == null // true
undefined == undefined // true
null == undefined // true
NaN은 그 자체가 동등하지 않다.
if (value !== value) {
console.log("we're dealing with NaN here")
}
Object 강제 변환
참고: JavaScript type coercion explained
덕 타이핑(Duck Typing)이란?
쉽게 정의를 하자면 사람이 오리처럼 행동하면 오리로 봐도 무방하다는게 덕 타이핑(Duck Typing) 이다.
타입을 미리 정하는게 아니라 실행이 되었을 때 해당 Method들을 확인하여 타입을 정한다는 것으로 타입 변화가 느슨하다.
- 장점
- 타입에 대해 매우 자유롭다.
- 런타임 데이터를 기반으로 한 기능과 자료형을 만들어 내는 것이다.
- 단점
- 런타임 자료형 오류가 발생할 수 있다. 런타임에서, 값은 예상치 못한 유형이 있을 수 있고, 그 자료형에 대한 무의미한 작업이 적용된다.
- 이런 오류가 프로그래밍 실수 구문에서 오랜 시간 후에 발생할 수 있다.
- 데이터의 잘못된 자료형의 장소로 전달되는 구문은 작성하지 않아야 한다. 버그를 찾기 어려울 수도 있다.
Reference
- How numbers are encoded in JavaScript
- What Every JavaScript Developer Should Know About Floating Point Numbers
- Here is what you need to know about JavaScript’s Number type
- The Secret Life of JavaScript Primitives
- Primitive Types
- (Not) Everything in JavaScript is an Object
- JavaScript data types and data structures - MDN
- Explaining Value vs. Reference in Javascript
- Primitive Types & Reference Types in JavaScript
- Value types, reference types and scope in JavaScript
- Back to roots: JavaScript Value vs Reference
- JavaScript Reference and Copy Variables
- (Not) Everything in JavaScript is an Object
- JavaScript type coercion explained
Function
Function에 대해 알아보기 전에 Javascript의 Scope를 알아보자. Javascript에서의 Scope는 크게 나누면 2개로 나뉘게 된다.
함수 안에서 정의가 된 변수들은 Local Scope에서 선언되었다고 하며, 함수 외부에 정의된 변수는 Global Scope에서 선언되었다고 한다.
함수 외부라고 하면 단순하게 중첩된 함수에서의 외부가 아닌 함수 1개가 있다는 기준에서의 외부이다.
이렇게 완전한 외부를 Window(Global) 라고 한다.
- Global Scope(함수 외부에 정의)
- Local Scope(함수 안에서 정의)
각각의 함수가 실행되면 내부적으로 새로운 Scope를 생성된다.
Global Scope
체감하지 못할 수 있지만, Javascript를 실행되는 순간부터 우리는 이미 Global Scope안에 있다.
Function 안쪽에서 선언하지 않는 것들은 Global Scope에서 선언된 것이다.
// Global Scope
const name = 'snyung';
const age = '27';
Global로 선언한 변수는 다른 Scope에서 접근이 가능하다.
const name = 'snyung';
// 같은 Scope에서의 호출은 된다.
console.log(name); // snyung
function logName() {
console.log(name); // name이라는 변수는 어디서든 접근이 가능하다.
}
logName(); // snyung
Local Scope
함수 안에서 선언한 변수는 Local Scope안에 있게 된다. 우리는 같은 변수의 이름을 다른 함수 내에서 정의할 수 있다.
해당 변수는 서로 다른 Scope에 바인딩 되며 같은 Level의 다른 함수에서는 접근할 수 없다.
// Global Scope
function someFunction() {
// Local Scope #1
function someOtherFunction() {
// Local Scope #2
}
}
// Global Scope
function anotherFunction() {
// Local Scope #3
}
// Global Scope
위와 같이 코드가 있다면, Local Scope#1에 선언한 변수는 Local Scope#2에서는 접근이 가능하지만, Local Scope#3에서는 접근이 불가하다.
마찬가지로 Local Scope#3에 선언된 변수는 Local Scope#1, Local Scope#2에서 접근이 불가하다.
Local Scope#2 에서 Local Scope#1 접근이 가능한 이유는 뒤에서 다룰 것이다.
Function Scope
Javascript는 위에서 본 것과 같이 함수 단위로 Scope를 구분한다. 즉, 같은 함수 안에서 선언된 변수들은 같은 Level의 Scope를 가지게 된다.
각각의 함수는 독립적인 Scope를 가지게 되어 다른 함수의 Scope에 접근할 수 없다.
function someFunction() {
if (true) {
var name = 'snyung'
}
console.log(name)
}
someFunction()
위와 같이 Global Scope에 someFunction()을 선언하고 내부에 if문 괄호 안에 선언한 변수는 someFunction Function Scope에 붙게 된다.
즉, block 단위가 아닌 function 단위의 scope가 정의된다.
Block Scope
Block Statement는 우리가 많이 보는 if문, switch문, for, while문이다. 이러한 문장들은 괄호로 감싸진 부분이 존재하지만 새로운 Scope를 만들지는 않는다. Block Statement 안에서 정의한 변수는 가장 가까운 함수의 Scope에 붙게 된다.
if (true) {
// 'if'문은 별도의 scope를 만들지 않는다.
var name = 'snyung' // name은 global scope에 만들어진다.
}
console.log(name) // logs 'snyung'
ECMAScript6에서 let, const가 추가되었다.
이는 var 대용으로 사용된다. 그러나 그보다 더 중요한 개념이 있다. 바로 Block Level Scope라는 것이다.
기존의 Javascript는 위에서 본 것처럼 Functional Scope 이다. 그러나 let, const 를 사용하게 되면 Block Level Scope 지원이 가능하다.
아래의 예제를 보자.
if (true) {
var name = 'snyung';
let likes = 'Coding';
const skills = 'Javascript';
}
console.log(name); // logs 'snyung'
console.log(likes); // Uncaught ReferenceError: likes is not defined
console.log(skills); // Uncaught ReferenceError: skills is not defined
var와는 다르게 let, const는 Block Statement내에서 Local Scope 를 지원한다. 즉, 이제 Scope가 가장 가까운 function에 붙는 것이 아닌 해당 Block Scope에 생성이 된다.
Global Scope는 응용 프로그램이 살아있을 때까지 유효하며, Block Scope는 함수가 호출되고 실행되는 동안 유지된다.
Lexical Scope
Lexical Scope는 중첩된 함수에서 내부 함수는 부모 Scope의 변수와 다른 자원에 접근이 가능하다. 즉, 하위 함수는 부모의 실행 컨텍스트에 바인딩 된다.
Lexical scope는 Static Scope라고도 불린다.
function grandfather() {
var name = 'snyung'
// likes is not accessible here
function parent() {
// name is accessible here
// likes is not accessible here
function child() {
// Innermost level of the scope chain
// name is also accessible here
var likes = 'Coding'
console.log(name)
console.log(likes)
}
child()
}
parent()
}
grandfather()
Function
함수는 Javascript에서 중요한 컨셉이다. Javascript에서 함수는 1급 객체이다.
- Function Declaration(함수 선언식)
- Function Expression(함수 표현식)
- Named Function Expression(이름이 있는 함수 표현식)
함수 선언식
function [name](param1, param2, ...param3) {
// Function Body & Logic
}
[function name] 앞에 [function keyword]를 붙인다. 항상 앞에 function으로 시작하며 함수의 이름을 지어주어야 한다. 선언식의 주요한 개념은 **호이스팅(Hoisting)**이 된다는 것이다.
호이스팅으로 인해서 함수를 선언하기 전에 함수를 실행하는 코드를 넣어도 작동하는 것이다.
이러한 선언 방법은 일부 논리를 함수 본문으로 추상화를 하고 나중에 실제 구현이 완료될 때 유용하다.
var num1 = 10;
var num2 = 20;
var result = add(num1, num2); // ==> 30 [Executing before declaring]
function add(param1, param2) {
return param1 + param2 ;
}
위와 같은 코드는 좋지 못하다. 항상 호이스팅을 이용하는 것이 아닌 함수를 먼저 선언을 하고 실행하는 습관을 들이는 것이 좋다.
함수 표현식
어떤 값을 다른 변수에 할당하는 명령문은 표현식으로 간주한다.
var a = 100;
var b = 'Hello World';
함수 표현식의 경우 이름이 없이 함수를 작성하며 변수에 할당한다.
var [name] = function(param1, param2, ...param3) {
// Function Body & Logic
}
foo(1,3,4);
함수 선언식과 다르게 정의될 때까지 함수를 사용할 수 없다. 즉, 호이스팅이 일어나지 않는다는 것을 의미한다. 정확하게 보면 변수는 호이스팅이 일어나지만, 할당이 이루어지는 행위는 호이스팅이 안 된다고 보는 것이 좋을 듯 하다.
var num1 = 10;
var num2 = 20;
var result = add(num1, num2);
// Uncaught TypeError: add is not a function
var add = function(param1, param2) {
return param1 + param2 ;
}
위와 같은 코드는 작동하지 않는다. 아래와 같이 작성을 하여야한다.
var num1 = 10;
var num2 = 20;
var add = function(param1, param2) {
return param1 + param2 ;
}
var result = add(num1, num2); // ==> 30
함수 표현식의 장점
선언식보다 표현식이 더 유용하게 사용되는 몇 가지 이유가 있다.
- As closures
- As arguments to other functions
- As Immediately Invoked Function Expressions (IIFE)
이름이 있는 함수 표현식 - 두 가지 접근 방식의 결합
선언식과 표현식의 차이점을 보고 두가지를 섞으면 어떻게 되는지 살펴보자.
var num1 = 10;
var num2 = 20;
var addVariable = function addFunction(param1, param2) {
return param1 + param2 ;
}
위에 코드를 보게 되면 표현식이 더이상 익명이 아니고 addFunction 이라는 이름을 가지고 있다. 또한 addVariable 이라는 변수명에 할당하였다.
우리가 함수의 이름으로 addFunction을 추가했다고 실행할 수 있는 것은 아니다.
var result = addFunction(num1, num2);
// ==> Uncaught ReferenceError: addFunction is not defined
우리가 할당한 addVariable 변수로만 사용이 가능하다.
var result = addVariable(num1, num2);
// ==> 30
고려해야 할 사항
addFunction이addVariable보다 콜스택상 먼저 나오게 된다.- 외부에서
addFunction을 호출하게 되면 에러가 나오게 된다.- 그러나 내부에서는
addFunction을 사용할 수 있다.
- 그러나 내부에서는
var num1 = 10;
var num2 = 20;
var addVariable = function addFunction(param1, param2) {
var res = param1 + param2;
if (res === 30) {
res = addFunction(res, 10);
}
return res;
}
var result = addVariable(num1, num2); // ==> 40
결과가 30이 아니라 내부적으로 addFunction 이 한번 더 호출되어 40이 나오게 된다.
- IE8이하에서는 이름이 있는 함수 표현식을 사용하게 되면 심각한 이슈가 발생하게 되는데, 바로 완전히 다른 두개의 함수객체를 생성한다는 것이다.(Double take).
IE8을 지원해야하는 일이 있으면 익명의 표현식을 사용하는 것을 추천한다.
Statements, Expressions
Expressions
Expressions는 단일값이 되는 Javascript 코드 Snippets이다. 표현식은 원하는만큼 길게 사용이 가능하지만 단일값이다.
2 + 2 * 3 / 2
(Math.random() * (100 - 20)) + 20
functionCall()
window.history ? useHistory() : noHistoryFallback()
1+1, 2+2, 3+3
declaredVariable
true && functionCall()
true && declaredVariable
위의 예제들은 모두 표현식이다. 흔히 값을 원할때 어디서든 사용하는 방법이다. 그래서 아래의 예제에서도 값이 단일값으로 나오게 된다.
console.log(true && 2 * 9) // 18
표현식은 상태를 변경하지 않는다.
var assignedVariable = 2; //this is a statement, assignedVariable is state
assignedVariable + 4 // expression
assignedVariable * 10 // expression
assignedVariable - 10 // expression
console.log(assignedVariable) // 2
위의 예제들은 표현식임에도 할당된 값은 마지막까지 2로 남는다. 함수 호출은 표현식이지만 함수 상태를 변경할 수 있는 문장은 필수적이다.
const foo = () => {
assignedVariable = 14
}
foo()는 표현식이지만 undefined나 다른 값을 반환한다. 그러나 이렇게 사용하게 됨으로써 상태를 변화시킬 수 있다.
const foo = () => {
return 14 //explicit return for readability
}
assignedVariable = foo()
더 좋은 방법은 아래와 같이 작성하는 것이다.
const foo = (n) => {
return n//explicit return for readability
}
assignedVariable = foo(14)
이렇게 작성을 하면 코드가 읽기 쉽게 구성이 가능하며 표현식과 명령문을 명확하게 구분할 수 있다. 이런 것이 선언적 Javascript의 근본이다.
Statements
기본적으로 문장은 행동을 수행한다.
Javascript에서 값이 필요한 곳에서는 명령문을 사용할 수 없다. 그래서 함수의 인수, 할당의 오른쪽, 연산자, 피연산자, 반환값으로 사용할 수 없다.
foo(if () {return 2})
명령문의 종류
- if
- if-else
- while
- do-while
- for
- switch
- for-in
- with (deprecated)
- debugger
- variable declaration
브라우저 콘솔창에서 아래와 같이 입력을 치게 되면,
if (true) { 9+9 }
18을 반환한다. 그러나 원하는 곳에 사용할 수 없다. 명령문은 아무것도 반환하지 않기를 바란다. 우리가 그것을 사용할 수 없다면 반환된 값은 쓸모가 없어지기 때문이다.
IIFE(Immediately Invoked Function Expression)
우리가 흔히 즉각 실행함수라 부르는 패턴이다. 이것을 사용하면 함수는 새로운 Scope를 만들게 된다. IIFE 는 단순하게 함수 표현식이다. 인터프리터가 즉각적으로 실행한다.
익명함수의 표현식과 비슷하게 생겼다.
var foo = 'foo';
(function bar () {
console.log('in function bar');
})()
console.log(foo);
위에서 간단하게 보면 foo가 출력되기 전에 bar()를 호출하지 않았는데 in function bar 가 출력이 되었다.
(괄호를 사용해서 함수를 감싸서 선언식이 아닌 표현식이 된다.- 마지막에
()괄호를 다시 써서 표현식을 즉시 실행하는 구문이 된다.
ES6 이전에는 IIFE를 사용해서 외부에서 접근하지 못하도록 변수를 숨기고 제한하는데 사용이 되었다. 또한 비동기 작업을 실행하고 IIFE 범위에서 변수상태를 보존하려는 경우에도 매우 유용하다.
for (var i = 0; i < 5; i++) {
setTimeout(function () {
console.log('index: ' + i);
}, 1000);
}
위에 코드는 흔히 발생하는 잘못된 코드이다. 이와 같은 코드를 IIFE를 사용해서 해결할 수 있다.
for (var i = 0; i < 5; i++) {
(function logIndex(index) {
setTimeout(function () {
console.log('index: ' + index);
}, 1000);
})(i)
}
그러나 ES6+를 사용한다면 Block Level Scope 를 지원하는 let 또는 const 를 사용하면 된다.
부록
Semi-colon vs Comma operator**
세미콜론을 사용함으로써 표현식을 표현식 문장으로 변환 시킬 수 있다. 2+2 자체는 표현식이지만 완전한 라인은 문장이다.
2+2 // on its own is an opposition
foo(2+2) //so you can use it anywhere a value is expected
true ? 2+2 : 1 + 1
function foo () {return 2+2}
2+2; //expression statement
foo(2+2;) //syntaxError
세미콜론을 사용하면 여러 줄을 한 줄로 표현이 가능하다.
const a; function foo () {}; const b = 2
쉼표 연산자를 사용하면 여러 표현식을 연결하여 마지막 표현식만 반환이 가능하다.
console.log( (1+2,3,4) ) //4
console.log( (2, 9/3, function () {}) ) // function (){}
console.log( (3, true ? 2+2 : 1+1) ) // 4
모든 표현식은 왼쪽에서 오른쪽으로 계산이 되고 마지막 표현식이 반환된다.
Reference
- Understanding Scope in JavaScript
- Understanding Scope in JavaScript
- Understanding Scope in JavaScript
- JavaScript Scope and Closures
- JavaScript Functions — Understanding The Basics
- All you need to know about Javascript's Expressions, Statements and Expression Statements
- Quick Tip: Function Expressions vs Function Declarations
- JavaScript Function — Declaration vs Expression
- Function Declarations vs. Function Expressions
Module
- Webpack, SystemJS 같은 도구는 무엇일까?
- AMD, UMD, CommonJS는 무엇인가?
- 이것들은 어떤 관련이 있는가?
- 왜 그걸 왜 필요로 하게 되었을까?
모듈이란?
모듈은 구현사항을 캡슐화하고 기능에 따라 Public API로 노출하여 다른 곳에서 쉽게 불러서 사용하도록 하며, 재사용이 가능하도록 한 코드 뭉치이다.
왜 모듈이 필요하게 되었을까?
- 추상적인 코드 : 전문 라이브러리에 기능을 위임하여 실제 구현의 복잡성을 이해할 필요가 없도록 하기 위해서
- 코드 캡슐화 : 코드를 변경하지 못하도록 하기 위해 모듈 내부의 코드를 숨기기 위해서
- 재사용 코드 : 같은 코드를 계속해서 사용하기 위해서
- 의존성 관리 : 우리의 코드를 다시 작성하지 않고 쉽게 종속성을 변경하기 위해서
Module patterns in ES5
기존의 자바스크립트는 모듈을 염두해두고 설계가 된 언어가 아니다. 시간이 지나면서 사람들이 필요에 따라 다양한 패턴을 만들게 된 것이다.
우리가 간단하게 볼만한 패턴은 IIFE와 공개 모듈 패턴이 있다.
즉시 실행 함수 표현(Immediately-invoked Function Expression)
IIFE는 ES5기준으로 가장 많이 사용되던 패턴 중 하나이다. Scope Block을 만드는 유일한 방법은 함수이기 때문이다. 따라서 아래와 같은 예제는 ReferenceError가 나온다.
(function() {
var scoped = 42;
}());
console.log(scoped); // ReferenceError
IIFE는 오픈소스라이브러리에서 Block scope를 만드는 데 사용되었다. 이렇게 하게 되면 우리가 만들면서 공개하는 것과 아닌 것을 구분할 수 있다.
var myModule = (function() {
// private variable, accessible only inside the IIFE
var counter = 0;
function increment() {
counter++;
}
// publicly exposed logic
return {
increment: increment
}
}());
ES6에서는 modules라는 스펙이 추가되어 modules를 사용할 수 있다. 현재 이 모듈은 자신의 범위를 선언하고 모듈 내부에서 생성된 변수는 전역객체에서 부를 수 없도록 한다.
!function() {
alert("Hello from IIFE!");
}();
위의 예제는 놀랍게도 IIFE이다. 우리가 흔히 알고 있는 모양새와 다르다고 생각해서 아니라고 할 수 있다. 그러나 우리가 사용하는 IIFE에서의 괄호는 표현식으로 나타내는 것에 불가하다. 그래서 표현식으로 나타낼 수 있는 어떤 것이든 생성 후 바로 실행이 되도록 하는 문장이 될 수 있는 것이다.
void function() {
alert("Hello from IIFE!");
}();
또한 void 역시 기본적으로 함수가 표현식으로 취급되도록 한다.
전통적인 IIFE
처음에 예제에서 보았듯이 IIFE 패턴의 핵심은 함수를 표현식으로 바꾸고 즉시 실행하는 것이다.
(function() {
alert("I am not an IIFE yet!");
});
위의 코드는 단순하게 함수를 괄호로 감싸고 있다. 그러나 이 함수식은 실행이 바로 되지 않으므로 즉시 실행 함수가 아니다. 이걸 IIFE로 바꾸기 위해서는 2가지의 스타일을 변환이 필요하다.
// Variation 1
(function() {
alert("I am an IIFE!");
}());
// Variation 2
(function() {
alert("I am an IIFE, too!");
})();
위의 예제에는 익숙한 문법이 있기도 하고 문법이 이상하다고 생각되는 것도 있다. 간단하게 살펴보면
- Variation 1의 4행에서 호출을 위한 괄호를 안쪽에 넣었다. 다시 바깥 괄호는 함수 밖의 함수 표현식을 만드는 데 필요하게 된다.
- Variation 2에서 마지막줄의 괄호는 함수 표현식을 호출하기 위한 괄호가 밖에 위치하고 있다.
두방법은 널리 사용되고 있다. 핵심부분으로 들어가게되면 2가지의 작동이 다르다. 그러나 상관없이 자신이 원하는 방법을 사용하면 된다.
작동하는 예제와 작동하지 않는 두가지 예제를 보자 익명의 함수를 사용하는 것은 좋은 방법이 아니므로 지금부터는 IIFE의 이름을 적어주자
// Valid IIFE
(function initGameIIFE() {
// All your magical code to initalize the game!
}());
// Following two are invalid IIFE examples
function nonWorkingIIFE() {
// Now you know why you need those parentheses around me!
// Without those parentheses, I am a function definition, not an expression.
// You will get a syntax error!
}();
function () {
// You will get a syntax error here as well!
}();
위의 예제를 실행하게 되면서 우리가 왜 괄호가 필요한지 알게될 것이다. IIFE를 만들려고 하면 우리는 표현식이 필요하다. 함수 선언, 함수 문장은 필요가 없다.
IIFEs and private variables
(function IIFE_initGame() {
// Private variables that no one has access to outside this IIFE
var lives;
var weapons;
init();
// Private function that no one has access to outside this IIFE
function init() {
lives = 5;
weapons = 10;
}
}());
IIFEs with a return value
var result = (function() {
return "From IIFE";
}());
alert(result); // alerts "From IIFE"
IIFEs with parameters
(function IIFE(msg, times) {
for (var i = 1; i <= times; i++) {
console.log(msg);
}
}("Hello!", 5));
Classical JavaScript module pattern
우리는 전체 시퀀스를 손상시키지않도록 작동하는 싱글톤 객체를 구현해보려고 한다.
var Sequence = (function sequenceIIFE() {
// Private variable to store current counter value.
var current = 0;
// Object that's returned from the IIFE.
return {
};
}());
alert(typeof Sequence); // alerts "object"
위의 예제를 간단하게 설명하면 sequenceIIFE라는 이름을 가진 함수를 표현식으로 나타내어 IIFE 패턴을 적용하였으며 private 변수로 current 를 선언해서 0을 담았으며 return으로 Object를 반환해서 Sequence라는 변수에 담고 있다. 그러므로 당연하게 그것의 타입은 object가 나오게 된다.
var Sequence = (function sequenceIIFE() {
// Private variable to store current counter value.
var current = 0;
// Object that's returned from the IIFE.
return {
getCurrentValue: function() {
return current;
},
getNextValue: function() {
current = current + 1;
return current;
}
};
}());
console.log(Sequence.getNextValue()); // 1
console.log(Sequence.getNextValue()); // 2
console.log(Sequence.getCurrentValue()); // 2
좀 더 그럴듯하게 꾸며보자. 위의 예제에서 return Object에 getCurrentValue, getNextValue 2가지의 함수를 만들어서 반환하고 있다. 그리고 후에 반환된 Object 의 함수를 실행시켜서 IIFE 안쪽에 current 값을 바꾸거나 가져오고 있다.
위의 current 라는 변수는 IIFE의 전용이므로, 클로저를 통해 접근할 수 있는 함수 외에는 변수를 수정하거나 직접 접근은 불가능하다.
이렇게 IIFE와 클로져를 같이 사용해서 구현해보았다. 이것은 모듈 패턴에 대한 매우 기본적인 변형이다. 더 많은 패턴이 존재하지만 거의 모든 패턴이 IIFE를 사용하여 폐쇄범위를 만든다.
When you can omit parentheses
var result = function() {
return "From IIFE!";
}();
함수 표현식 주위의 괄호는 기본적으로 함수가 명령문이 아닌 표현식이 되도록 한다. 위의 예에서 function 키워드는 명령문의 첫 단어가 아니라서 자바스크립트가 이걸 선언문이나 정의로 취급하지 않는다. 마찬가지로 표현식이라는 것을 알 경우 괄호를 생략할 수 있다.
그러나 다른 개발자들분들도 그렇게 생각할지 모르지만, 항상 괄호를 붙이는 것이 가독성에 좋다.
싱글톤 대신 모듈로 구현하여 생성자 함수를 노출할 수도 있다.
// Expose module as global variable
var Module = function(){
// Inner logic
function sayHello(){
console.log('Hello');
}
// Expose API
return {
sayHello: sayHello
}
}
var module = new Module();
module.sayHello();
// => Hello
Module formats
기존의 ES6이전에는 자바스크립트에 모듈을 정의하는 공식문법이 존재하지 않았다. 그래서 다양한 모듈을 정의해왔었는데
- Asynchronous Module Definition (AMD)
- CommonJS
- Universal Module Definition (UMD)
- System.register
- ES6 module format
Asynchronous Module Definition (AMD)
AMD 형식은 브라우저에서 사용되며 정의함수를 사용하여 모듈을 정의한다.
//Calling define with a dependency array and a factory function
define(['dep1', 'dep2'], function (dep1, dep2) {
//Define the module value by returning a value.
return function () {};
});
CommonJS format
CommonJS 형식은 Node.js에서 사용되며 require과 module.exports를 사용하여 종속성, 모듈을 정의한다.
var dep1 = require('./dep1');
var dep2 = require('./dep2');
module.exports = function(){
// ...
}
Universal Module Definition (UMD)
UMD는 브라우저와 Node에서 모두 사용이 가능하다.
(function (root, factory) {
if (typeof define === 'function' && define.amd) {
// AMD. Register as an anonymous module.
define(['b'], factory);
} else if (typeof module === 'object' && module.exports) {
// Node. Does not work with strict CommonJS, but
// only CommonJS-like environments that support module.exports,
// like Node.
module.exports = factory(require('b'));
} else {
// Browser globals (root is window)
root.returnExports = factory(root.b);
}
}(this, function (b) {
//use b in some fashion.
// Just return a value to define the module export.
// This example returns an object, but the module
// can return a function as the exported value.
return {};
}));
System.register
System.register형식은 ES5에서 ES6 모듈 구문을 지원하도록 설계되었다.
import { p as q } from './dep';
var s = 'local';
export function func() {
return q;
}
export class C {
}
ES6 module format
// lib.js
// Export the function
export function sayHello(){
console.log('Hello');
}
// Do not export the function
function somePrivateFunction(){
// ...
}
사용하려면 import로 불러서 사용한다.
import { sayHello } from './lib';
sayHello();
// => Hell
아직 브라우저는 ES6문법을 지원하지 않는다. 이미 ES6 모듈 포맷을 사용할 수 있지만, 브라우저에서 코드를 실제로 실행하기 전에 코드를 AMD나 CommonJS와 같은 ES5 모듈 형식으로 바꾸기 위해 Babel과 같은 변환기가 필요하게 된다.
Module loaders
모듈 로더는 특정 모듈 형식으로 작성된 모듈을 해석하고 load한다.
런타임 시점에 loader를 실행한다.
- 브라우저에서 모듈 로더를 로드한다.
- 모듈 로더에게 어느 파일을 로드할 것인지 알려준다.
- 모듈 로더가 주파일을 다운로드해서 해석한다.
- 필요한 경우에는 모듈 로더가 파일을 다운로드한다.
널리 사용되는 모듈 로더는 아래와 같이 있다.
- RequireJS : AMD 형식의 모듈용 로더
- SystemJS : AMD, CommonJS, UMD 또는 System.register 형식의 모듈용 로더
Module bundlers
모듈 번들러는 모듈 로더를 대체한다. 그러나 로더와 차이점은 모듈 번들은 빌드시에 실행된다.
- 빌드할 때 모듈 번들을 실행하여 번들파일을 생성한다.
- 브라우저에서 번들을 로드한다.
널리 사용되는 모듈 번들러는 아래와 같이 있다.
- Browserify : CommonJS 모듈용 bundler
- Webpack : AMD, CommonJS, ES6 모듈용 bundler
Reference
- Essential JavaScript: Mastering Immediately-invoked Function Expressions
- Do ES6 Modules make the case of IIFEs obsolete?
- JavaScript Modules: A Beginner’s Guide
- ES6 modules, Node.js and the Michael Jackson Solution
- A 10 minute primer to JavaScript modules, module formats, module loaders and module bundlers
- JavaScript Modules: A Beginner’s Guide
Event Loop
자바스크립트는 싱글 쓰레드이다. 그래서 비동기를 처리하기 위해서는 다른 누군가의 도움이 필요하다.
우리가 자바스크립트를 기본적으로 브라우저에서 사용을 한다. 그렇다면 당연하게 자바스크립트의 한계를 보완해주는 역할은 브라우저가 해준다는 것이다. 브라우저가 해주는 많은 역할 중 하나는 비동기처리를 도와주는 것이다.
오늘은 비동기를 처리하는데 있어서 큰 역할을 하고 있는 것을 알아보도록 하자.
목차
- Heap
- Stack
- Browser or Web APIs
- Event Table
- Event Loop
자바스크립트는 스크립트가 실행이 되는 엔진이 있다. 크롬을 기준으로 본다면 엔진은 V8이 된다. 이 엔진을 구성하는 요소는 크게보면 Heap과 Stack으로 구성이 되어있다.
Heap
객체는 Heap에 할당이 된다. Heap은 메모리에서 대부분 구조화되지 않은 영역을 나타낸다.
Stack
자바스크립트 코드 실행을 위해 제공된 단일 쓰레드이다. 함수를 호출하게 되면 하나의 Stack Frame이 형성이 된다.
더이상의 자세한 내용은 CallStack에 대해서 작성한 글을 참고 해주세요.
Browser or Web APIs
흔히 WebAPI라 불리는 API들은 웹 브라우저에 내장되어 있으며 브라우저 및 이외 컴퓨터 환경에서 데이터를 노출 할 수 있으며 복잡한 환경에서 유용하게 사용할 수 있다.(ex. 위치정보등등)
이것은 자바스크립트에 포함되는 것이 아니며 자바스크립트 언어를 사용하는데 있어 강력한 성능을 제공한다.
예제로 살펴보기
function main(){
console.log('A');
setTimeout(
function display(){ console.log('B'); }
,0);
console.log('C');
}
main();
// Output
// A
// C
// B

- main함수가 실행이 되어서 처음에 들어가게 된다. main함수 안에 있는
console.log가 스택에 쌓이게 된다. 함수가 실행이 되면 알파벳이 콘솔창에 출력이 된다. - 다음으로
setTimeout이 들어오면서 실행이 된다.setTimeout은browserAPI의 콜백을 지연하는 함수를 사용한다. - 브라우저에서 타이머가 이루어지는 동안
console.log가 실행이 되고 C가 출력이 된다. 여기서 초가 0이더라도 콜백은 메시지 큐에 담기게 되어 브라우저는 그것을 받는다. - main함수가 모두 다 끝나게 되면 스택이 비게 된다. 그러면 브라우저가 큐에 쌓았던 콜백을 실행하게 된다.
스택이 비었을때 자바스크립트 엔진은 메시지 큐가 비었는지 확인을 한다. 만약에 비었다면 엔진은 첫번째 메시지를 지우고 함수의 안을 실행한다. 이때 새로운 스택프레임(inital frame)이 생성이 되고 스택에 쌓인다. 함수가 끝났다면 initial 프레임이 스택에서 제거가 된다. 이러한 과정은 메시지 큐가 없을 때까지 이루어진다.
The Event Loop
위에서 언급을 했던 끊임없이 비었는지 검사하는 것이 바로 이벤트 루프이다. 이벤트 큐에 대기중인 항목이 있으면 호출 스택으로 이동한다. 그렇지 않으면 아무일도 일어나지 않는다.
setTimeout(() => console.log('first'), 0)
console.log('second')
위의 경우는 second가 찍히고 first가 찍히게 된다.
멀티쓰레드라면 하나의 일을 하고 있을 때 다른 쓰레드를 사용해서 일을 처리할 수 있지만 자바스크립트는 싱글쓰레드이기 때문에 불가능하다. 그래서 비동기를 하는데 있어서 이벤트 루프는 필수적이다.
while (await messageQueue.nextMessage()) {
let message = messageQueue.shift();
message.run();
}
이벤트 루프는 메시지 큐에 메시지가 더 있는지 확인하는 루프이다.
메시지 큐에 메시지가 있으면 메시지 큐에서 다음 메시지를 제거하고 그 메시지와 연관된 기능을 실행한다. 그렇지 않으면 새 메시지가 메시지 대기열에 추가 될때까지 대기를 한다. 이벤트루프가 자바스크립트에게 비동기를 허용하는 기본 모델이다.
Reference
- JavaScript Event Loop Explained
- What is the Event Loop in Javascript
- Understanding JS: The Event Loop
- Event loop in javascript
- The JavaScript Event Loop
- Tasks, microtasks, queues and schedules
Async
자바스크립트는 기본적으로 싱글 쓰레드이다. 이 말을 쉽게 하면 한번에 1가지의 일을 할 수 밖에 없다. 간단한 예제를 들자면 우리가 요리를 한다고 하면, 야채를 썰면서 물을 끓이는 행위를 동시에 할 수 없다는 것을 뜻한다. 이러한 불편한 점을 알았는지 벤더들은 자바스크립트의 싱글 쓰레드를 확장 시켜줄 API를 만들어 주었다.
- setInterval
- setTimeout
- requestAnimationFrame
- requestIdleCallback
setInterval
자바스크립트는 브라우저 내에서 작동하며 기본 동작은 2번째 인자로 받은 ms 마다 1번째 인자로 받은 CallBack Function 을 실행하는 것을 전제로 한다.
setInterval 이 실행이 되면 WEB API에서 시간을 기다리고 있다가 특정시간 마다 큐에 넣게 된다. 그러나 이것은 CallStack 이 비어있어야 하며 다른 작업을 계속해서 하고 있다면 한 없이 기다리게 될 수도 있다.
이렇게 setInterval 은 지연이 발생할 수 있으며 시간에 따라 증가하게 된다.
이러한 이유는 3가지로 정리 할 수 있다.
- 앱을 실행하는 기기의 하드웨어 제한사항
- 브라우저의 비활성탭에서 실행되도록 앱남기기(멈추지 않고 계속해서 실행이 된다.)
- 최적화되지 않은 전체 코드베이스

위의 사진을 간단하게 보면 dummyMethod1() 이 오래 걸리면 자바스크립트의 이벤트 루프는 본연의 특징으로 인해서 스택에 걸려버렸다. 이런 상황이 되면 실행하기 위해서 기다리는 방법밖에 없다.
이렇게 우리가 조작을 할 수 없는 3번의 순간에 보낸다. 타이머라는게 이상적인 상황일 때는 우리가 생각하는 그 시간에 갈 수 있지만 브라우저와 자바스크립트는 그렇게 이상적이지 않다.
setTimeout
setTimeout 은 setInterval 을 한 번 실행하는 것과 동일하다.

위에서 했던 내용을 이번에는 setTimeout 의 재귀적 호출로 해보자 그렇게 된다면 결국 setTimeout 의 CallBack Function 에 setTimeout 이 다시 불리는 구조가 될 것이다. 이렇게 만들어서 실행을 한다면 우리가 생각했던 것과 더욱이 달라질 것이다. setInterval 은 내가 정한 시간에 맞춰서 CallBack을 실행 하려고 큐에 담았을 것이다. 그러나 setTimeout 은 callback function이 불려야 다음 setTimeout 이 실행이 될 수 있는 조건이 되어 interval 보다 지연이 더 심해 질 수 있다.
지연예시
var counter = 0;
var fakeTimeIntensiveOperation = function() {
for(var i =0; i< 50000000; i++) {
document.getElementById('random');
}
let insideTimeTakingFunction = new Date().toLocaleTimeString();
console.log('insideTimeTakingFunction', insideTimeTakingFunction);
}
var timer = setInterval(function(){
let insideSetInterval = new Date().toLocaleTimeString();
console.log('insideSetInterval', insideSetInterval);
counter++;
if(counter == 1){
fakeTimeIntensiveOperation();
}
if (counter >= 5) {
clearInterval(timer);
}
}, 1000);
//insideSetInterval 13:50:53
//insideTimeTakingFunction 13:50:55
//insideSetInterval 13:50:55 <---- not called after 1s
//insideSetInterval 13:50:56
//insideSetInterval 13:50:57
//insideSetInterval 13:50:58
requestAnimationFrame
기본적으로 브라우저는 60FPS 이다 그래서 1초에 60번을 실행하게 되면 애니메이션이 깔끔하게 보인다. 그렇다면 위에서 알게 된 setInterval 을 사용해서 표현을 하면
setInterval(function() {
// animiate something
}, 1000/60);
이런식으로 표현이 가능하다. 그러나 위에서 언급을 했지만 문제가 있다.
이에 2017년 requestAnimationFrame 이라는 기능이 크롬의 Paul Irish에 의해서 추가가 되었다.
Paul의 설명에 의하면
- 브라우저가 애니메이션을 최적화 할 수 있으므로 애니메이션이 부드럽게 처리될 수 있다.
- 비활성 탭의 애니메이션이 중지되어 CPU가 시원해진다.
- 더욱이 배터리 친화적이다.
가장 간단한 예제를 보면
function repeatOften() {
// Do whatever
requestAnimationFrame(repeatOften);
}
requestAnimationFrame(repeatOften);
한번 실행하면 재귀적으로 호출한다.
requestAnimationFrame 역시 취소하기 위햇 setTimeout setInterval과 마찬가지로 ID를 반환한다.
globalID = requestAnimationFrame(repeatOften);
cancelAnimationFrame(globalID);
그러나 아래의 링크를 보면 알게되지만 모든 브라우저가 지원하는 것은 아니다.
브라우저 지원여부 확인하기(https://caniuse.com/#feat=requestanimationframe)
예제
https://codepen.io/seonhyungjo/pen/MRVPxL
이외의 Async
requestIdleCallback
Observer
- mutation
- resize
- intersection
- performance
Reference
- https://javascript.info/settimeout-setinterval
- https://dev.to/akanksha_9560/why-not-to-use-setinterval--2na9
- https://develoger.com/settimeout-vs-setinterval-cff85142555b
- https://www.amitmerchant.com/Handling-Time-Intervals-In-Javascript/
- https://css-tricks.com/using-requestanimationframe/
- http://www.javascriptkit.com/javatutors/requestanimationframe.shtml
- https://yoiyoy.wordpress.com/
JavaScript Engine
목차
- 자바스크립트 엔진 파이프라인
-
V8
- 이그니션
- 터보팬
- 이전의 엔진
- 히든 클래스
- 인라인 캐싱
- 최적화
JavaScript Engine이란?
JS코드를 실행하는 프로그램(가령 브라우저) 또는 인터프리터 를 말한다.
V8
제일 유명하고 사람들이 많이 사용하는 크롬에 들어가있는 V8 이 있다. 현재 Electron, Nodejs 에서도 사용이 되고 있고 CEF의 안에도 들어있다.
SpiderMonkey
최초의 자바스크립트 엔진 으로, JS의 창시자인 브랜던 아이크가 넷스케이프 브라우저를 위해 개발이 되었다. 지금은 Mozilla 재단에서 관리하며, FireFox 에서 사용되는 엔진이다.
Chakra
마이크로소프트가 개발한 엔진 이며, Edge 브라우저에 사용되고 있고 앞으로는 V8로 바꾼다는 말이 있다.
Chakra 엔진의 중요 부분은 Chakra Core 라는 오픈 소스로 구성되어있다.
Javascript Core
애플에서 개발한 JavaScriptCore는 처음에 WebKit 프레임워크 를 위해 개발. 최근에는 Safari와 React Native App에서 사용된다고 한다.
자바스크립트 엔진 파이프라인
소스코드를 기계어로 만드는 과정에 대해서 알아보려고 한다.
- 자바스크립트 소스를 파싱해서 AST로 만든다.
- AST를 토대로 인터프리터는 바이트코드로 만들어준다.
코드를 더 빨리 실행하기 위해서, 바이트코드는 프로파일링 된 데이터와 함께 optimizing compiler 로 보내지고 여기서는 프로파일된 데이터를 기반으로 하여 최적의 기계어를 생성 하게 된다.
바이트 코드 + 프로파일된 데이터 => 최적의 기계어
그러나 정확하지 않은 결과가 나왔다면 다시 deoptimizes하여 바이트코드로 되돌린다.

위의 파이프라인 작동하는 방식은 Chrome 및 Node.js에서 사용되는 JavaScript 엔진이 작동하는 방식과 거의 동일하다.

V8의 인터프린터 Ignition 이라고 불리며, bytecode 를 생성하고 실행하는 역할을 한다. Bytecode 를 실행하는 동안, 실행 속도를 높이기 위해서 profiling data 를 수집한다. 예를 들어, 종종 실행되는 기능에 부하가 걸리면, 생성된 bytecode 와 profiling data 는 TurboFan(최적화된 컴파일러)으로 전달되어 profiling data 를 기반으로 최적화 머신 코드( optimized code )를 생성합니다.
V8 살펴보기
V8.5.9 이전
내용이 많아 자세히 설명해주신 블로그 링크를 넣었습니다.
https://engineering.huiseoul.com/자바스크립트는-어떻게-작동하는가-v8-엔진의-내부-최적화된-코드를-작성을-위한-다섯-가지-팁-6c6f9832c1d9
JavaScript Engine이 객체 모델을 구현하는 방법
객체는 JavaScript 명세에 따르면 String으로 된 키와 이것으로 접근할 수 있는 값들을 가지고 있는 딕셔너리(Key-Value)이다. 키는 단순히 [[value]] 에 맵핑되는 것 뿐만 아니라 속성 값(property attributes) 이라고 하는 스펙에도 매핑이된다.

객체는 기본적인 속성 값으로 [[Writable]], [[Enumerable]], [[Configurable]] 상태가 있다.
- Writable : 할당연산자를 통해 값을 바꿀 수 있는지
- Enumerable : 해당 객체의 키가 열거 가능한지
- Configurable : 이 속성 기술자는 해당 객체로부터 그 속성을 제거 할 수 있는지
어떤 객체나 속성이든 Object.getOwnPropertyDescriptor API를 이용해 이 값들에 접근할 수 있습니다.
const object = { foo: 42 };
Object.getOwnPropertyDescriptor(object, 'foo');
// => {value: 42, writable: true, enumerable: true, configurable: true}
JavaScript 배열
배열은 조금 다르게 처리하는 특별한 객체라고 생각하면 됩니다.객체와 다른 배열만의 특징은 다음과 같습니다.
- 인덱스(index)가 존재한다.
인덱스는 제한된 범위가 있는 정수로. JavaScript 명세에 따르면, 배열은 2³²−1 개 까지의 아이템을 가질 수 있다. 따라서 배열 인덱스는 0 부터 2³²−2 까지의 범위에서만 인덱스로 유요한 정수라는 것이다.
- 길이(length) 정보를 가집니다.
length property 는 배열에 추가하면 length property 는 저절로 늘어난다. 사실 엔진에서 자동으로 해주는 것이다.
const array = ['a', 'b'];
array.length; // 2
array[2] = 'c';
array.length; // 3
JavaScript 엔진에서 배열을 다루기
객체와 비슷하다. 배열은 인덱스를 포함하여 모두 string 키를 가진다. 아래 그림을 보면 인덱스인 0 은 a 라는 값을 가지며, 값을 바꿀 수 있고(Writable), 열거 가능하고(Enumerable), 삭제 가능(Configurable) 하다. 또 다른 프로퍼티인 length 의 값은 1이며, 값을 바꿀 수 있지만 열거와 삭제가 불가능 하다.

배열에 Item을 추가하게 되면, JavaScript 엔진은 length의 속성 값 중 [[value]]를 자동으로 증가시킨다.

Hidden Class(Shape)
function logX(obj){
console.log(obj.x);
}
const obj1 = { x:1, y:2 };
const obj2 = { x:3, y:4 };
logX(obj1);
logX(obj2);
동일한 프로퍼티 x와 y를 string 키로 가지는 두 객체가 있다면. 이 두 객체의 모양(shapes)은 똑같다.
함수 logX를 통해 두 객체 각각에서 같은 프로퍼티 x 에 접근한다. JavaScript 엔진은 프로퍼티 접근 시에 모양이 같은 점을 이용하여 최적화를 한다.

객체의 키 x, y는 각각의 속성 값(property attributes)을 가리킨다. 예를 들어 x 프로퍼티에 접근하게 되면 엔진은 Object 에서 x 키를 찾은 다음, 해당하는 속성 값을 불러오고 [[Value]] 값을 반환한다.
여기서 5와 6 같은 데이터는 어디에 저장되나?
모든 객체 별로 정보를 저장하게 되면 낭비가 된다. 비슷한 모양의 객체가 더 많이 생긴다면, 그만큼의 중복할 발생할 것이고 필요없는 메모리 사용이 늘어나게 되는 것이다.
그래서 엔진은 직접 값을 저장하는 방법 아래와 같은 방법을 사용하게 된다.

우선 엔진은 따로 Shape 라는 곳에 프로퍼티 이름과 속성 값들을 저장한다. 여기에 [[value]] 값 대신 JSObject 의 어디에 값이 저장되어 있는지에 대한 정보인 Offset 을 Property information으로 가지고 있는다.

즉, 같은 모양을 가진 모든 JSObject는 동일한 Shape 인스턴스를 가리키게 되고, 각 객체에는 고유한 값만 저장되므로, 더 이상 중복되지 않는 것이다. 같은 모양으로 생긴 더 많은 오브젝트가 있다 하더라도 오로지 하나의 Shape 만 존재하게 된다.
Shape에 새로운 객체를 추가하기 (Transition chains)
이런 Shape가 있다고 합시다.
const o = {};
o.x = 5;
o.y = 6;
새로운 프로퍼티를 추가할 때, 엔진은 어떻게 새로운 Shape를 찾을수 있는 것일까? 엔진은 내부에 transition chains라고 하는 Shape를 만든다.
먼저, 비어있는 객체인 o가 있으며, 이는 비어있는 Shape를 가리킨다.

여기에 5라는 값을 가진 x 라는 프로퍼티를 추가하게 되면, 비어있던 Shape에서 x 를 프로퍼티로 가지고 있는 새로운 Shape로 이동(transition)하게 된다. 다음과 같이 JSObject 의 값이 추가되고, offset 은 0이다.

새로운 프로퍼티 y를 추가해도 똑같이 작동하게 된다. Shape(x,y) 로 이동한 다음 값을 추가한다.

하지만 이런 방법을 모든 테이블에 항상 적용했다가는 많은 메모리 낭비를 일으키겠지요. 그래서 실제로 엔진은 이렇게 동작하지 않습니다.
실제로 엔진에서 동작하는 방법
엔진은 추가되는 새로운 프로퍼티 정보를 저장하고, 이전 Shape로 가는 링크를 제공한다. 만약 o.x를 찾을 때 값이 Shape(x,y) 에 없다면 이전의 Shape(x)에 가서 찾는 것이다.

두 객체에서 동일한 Shape를 사용하는 경우 (Transition Tree)
만약에 두 객체에서 동일한 Shape를 사용한다면 어떻게 될까? 먼저 하나의 객체 a 에 x = 5 라는 값을 가진 프로퍼티가 있다고 하면

이번엔 객체 b 에서 y 라는 프로퍼티를 추가할 경우 Shape(empty)에서 가지를 뻗어 새로운 Shape(y)를 만든다. 결국 2개의 체인에 3개의 Shape를 가진 트리 체인이 생성되는 것이다.

java의 Object처럼 모든 객체의 트리를 거슬러 올라가면 무조건 Shape(empty)에 도달하게 되는 것은 아니다.
const obj1 = {};
obj1.x = 6;
const ob2 = {x: 6};
ojb2 와 같이, JS에서는 Object Literal 을 사용하여 시작부터 프로퍼티를 가지고 생성하도록 할 수 있기 때문이다. 따라서 Shape(empty)가 아닌, 서로 다른 Root Shape가 생성된다.

이 방법은 transition chain 을 짧게 하고, 객체를 리터럴로부터 생성하여 더욱 효율적이다. point는 x,y,z 를 3차원 공간의 좌표로 가지는 객체이다.
const point = {};
point.x = 4;
point.y = 5;
point.z = 6;
앞서 배운 것에 따르면, 총 3개의 Shape가 메모리에 생성 될 것입니다. (empty Shape 제외)

만약 이걸 사용하는 프로그램에서 x 프로퍼티에 접근한다고 하면, 엔진은 가장 마지막에 생성된 Shape(x,y,z) 부터 링크드 리스트를 따라올라가 맨 위에 있을 x 를 찾는다.
객체의 프로퍼티가 더 많을수록, 그리고 이 과정을 자주 반복한다면 프로그램은 상당히 느려질 것이다.
그래서 엔진은 탐색 속도를 높이기 위해 내부적으로 ShapeTable 이라는 자료구조를 추가한다. 이는 딕셔너리 형태로, 각각의 Shape를 가리키는 프로퍼티 키를 저장하고 있다.

그렇다면 기껏 Shape가 나온 이유가 없어지는 것인가? 사실 엔진은 최적화를 위해 또 다른 방법인 Inline Cache(IC) 라는 것을 Shape에 적용한다.
Chrome dev_tool Memory Tab에서 예제를 확인해보자!!!
:point_right: 예제
function Person(name) {
this.name = name;
}
var foo = new Person("yonehara");
var bar = new Person("suzuki");
:point_right: 예제2
function Person(name) {
this.name = name;
}
var foo = new Person("yonehara");
var bar = new Person("suzuki");
foo.job = "frontend";
Inline Cache(ICs)
Shape를 사용하는 주된 이유는 Inline Caches(ICs) 때문이다. ICs 는 JavaScript를 신속하게 실행할 수 있게하는 핵심 요소이다. JavaScript 엔진은 ICs를 사용하여 object에서 property를 찾을 수 있는 위치에 대한 정보를 암기하여, 높은 cost를 가지는 조회 횟수를 줄인다.
function getX(o) {
return o.x;
}
위의 함수를 JSC 에서 실행한다면, 아래의 그림과 같은 bytecode 를 생성할 것이다.

첫 번째 명령문 get_by_id는 첫 번째 argument (arg1) 에서 property 'x' 를 로드하여 결과를 loc0 에 저장한다.
두 번째 명령문은 loc0 에 저장한 것을 반환한다.
또한 JSC 는 get_by_id 명령문에 초기화되지 않은 두 개의 슬롯으로 구성된 Inline Cache 를 포함한다.

이제 위의 그림과 같이 {x: 'a'} object 가 getX 함수에서 실행될 때를 보게 되면, object 는 property 'x' 가 있는 shape를 가지며, 이 Shape는 property x 에 대한 offset 과 attribute 들을 가집니다. 이 함수를 처음 실행하면, get_by_id 함수 는 property 'x' 를 검색하고 value는 offset 0 에 저장되어 있다는 것도 찾게된다.

위의 그림에서 처럼 get_by_id 명령문에 포함된 IC는 property 가 발견된 shape와 offset을 기억하게 된다.

위의 그림을 보게되면, 다음 명령문을 실행할 때, IC는 shape만 비교하면 되며, 이전과 같다면 저장되어있는 offset을 보고 value를 가져오면 된다. 구체적으로 말하면, 엔진이 IC가 이전에 기록한 shape의 object를 볼 경우, 더 이상 property 정보에 접근할 필요가 없다. 그리고 비용이 많이 들어가는 property 정보 조회를 완전히 생략하게 된다. 이 방법은 매번 property를 조회하는 것 보다 훨씬 더 빠르다.
어떻게 최적화된 자바스크립트 코드를 작성할 것인가
- 객체 속성의 순서 : 객체 속성을 항상 같은 순서로 초기화해서 히든클래스 및 이후에 생성되는 최적화 코드가 공유될 수 있도록 한다.
- 동적 속성: 객체 생성 이후에 속성을 추가하는 것은 히든 클래스가 변하도록 강제하고 이전의 히든클래스를 대상으로 최적화되었던 모든 메소드를 느리게 만든다. 대신에 모든 객체의 속성을 생성자에서 할당한다.
- 메소드 : 동일한 메소드를 반복적으로 수행하는 코드가 서로 다른 메소드를 한 번씩만 수행하는 코드 보다 더 빠르게 동작합니다(인라인 캐싱 때문)
- 배열 : 값이 띄엄띄엄 있어서 키가 계속해서 증가하는 숫자가 되지 않는 배열은 피하는게 좋다. 모든 요소를 가지지는 않는 배열은 해시테이블이다. 이와 같은 배열의 요소들은 접근하기에 많은 비용이 든다. 또한 커다란 배열을 미리 할당하지 않도록 하는 것이 좋다. 사용하면서 크기가 커지도록 하는 게 좋다. 마지막으로 배열의 요소를 삭제하지 말아야한다. 그 배열의 키가 띄엄띄엄 배치된다.
- 태깅된 값 : V8은 객체와 숫자를 32비트로 표현한다. 어떤 값이 오브젝트(flag = 1)인지 혹은 정수(flag = 0)인지는
SMI(Small Integer)라는 하나의 비트에 저장하고 이 때문에 31비트가 남는다. 따라서 어떤 숫자가 31비트 보다 크면 V8은 이 숫자를 분리해서 더블 타입으로 전환한 다음 이 숫자를 넣을 새로운 객체를 생성한다. 이러한 동작은 비용이 높으므로 가능한한 31비트의 숫자를 사용하자.
Reference
- JavaScript essentials: why you should know how the engine works
- 자바스크립트는 어떻게 작동하는가: V8 엔진의 내부 + 최적화된 코드를 작성을 위한 다섯 가지 팁
- Understanding V8’s Bytecode
- Understanding How the Chrome V8 Engine Translates JavaScript into Machine Code)
- V8의 히든 클래스 이야기
- https://shlrur.github.io//javascripts/javascript-engine-fundamentals-shapes-and-Inline-caches/
Bitwise Operator
우리가 흔히 AND를 표현할 때 && 를 사용하며 OR을 표현할때 || 를 사용한다. 왜 두 개씩 사용해서 표현을 하는 것일까? 하나로는 표현이 안되는 것인가?
이유는 한 개를 사용하는 &, |는 비트연산자에서 사용이 되고 있기 때문이다.
Bits(비트)란?
비트는 숫자나 문자 또는 문자열과 함께 작동하지 않으며 이진 숫자만 사용한다. 쉽게 말하면 모든 것이 이진 형식으로 저장된다. 저장된 이진형식은 컴퓨터에서 UTF-8과 같은 인코딩을 사용하여 저장된 비트 조합을 문자, 숫자 또는 다른 기호에 Mapping한다.
당연히 가지고 있는 비트가 많을수록 더 많은 순열과 더 많은 것을 표현할 수 있다.
자바스크립트에서 우리가 비트를 얻는 방법은 간단하다. 가령 숫자 하나가 있다면 (Number).toString(2) 를 하게 되면 얻어오게 된다. 자바스크립트에서 바이너리를 직접 입력 할 수 있는 방법이 없다 이진수를 10진수로 변환하려면 parseInt(111,2) 를 해야한다.
Bitwise Operator(비트연산자)란?
비트 수준에서 변수와 상호 작용하는 방법이다. 비트는 부동소수점, 정수로 변환되므로 정보를 쉽게 소화가능하다. 속도와 효율성을 중요시한다면 비트로 직접 처리, 변환하는 것이 유용하다.
비트 연산자(AND, OR, XOR)는 일반 논리연산자와 비슷하게 동작한다. 비트 수준에서는 일반적으로 논리를 해석하는 방식이 아니라 비트 수준에서 평가를 한다.
비트 연산자를 사용하면 어떤 이점이 있을까? 비트 수준에서의 평가는 일반적인 논리연산자보다 빠르기 때문에 큰 샘플에 대한 평가 또는 반복은 비트 연산이 더욱 효율적이다.
& (AND)
&& 논리 연산자와 매우 비슷하다. 비교되는 비트가 둘 다 1인 경우 1을 반환한다. 가령 12와 15가 있다면 각각 1100과 1111 이다. 그것을 &연산자를 사용한다면 1100을 얻는다. 결과는 12가 나오게 된다.
하나의 Trick(트릭)으로 숫자가 짝수인지 홀수인지를 알아낼 수 있다. 숫자가 홀수인 경우 첫번째 비트는 항상 1이다. 따라서 &를 사용하여 1과 비교할 수 있다. 그러나 실제로는 사용하지 않는 것을 추천한다.
| (OR)
|| 논리 연산자와 매우 비슷하다. 비교되는 비트가 모두 0이거나 0과 1이 하나씩 있을 경우 1을 반환한다. 비트별로 이진수를 비교하는데 사용이 된다. 예제에 |연산자를 사용하면 15가 반환된다.
1100 | 1111는 비교를 하면 각각에 대해 1를 반환하여 15이 된다.
~ (NOT)
모든 비트를 1은 0으로 0은 1로 바꾼다. 즉 무엇이든 반대로 되돌린다는 것이다. 그런데 ~15 를 하게 되면 이상하게 결과가 -16이 나오게 된다. 이유는 2의 보수연산에서 숫자의 음수 표현을 얻으려면 먼저 비트를 뒤집어서 1을 더해야 하기 때문이다.
^ (XOR)
이 연산자는 XOR 연산자 또는 배타적 OR연산자라고 불린다. &과 | 같은 연산자는 양측의 숫자를 가져와서 비교하는 방식으로 이 연산자와는 차별화된다. 해당 비트를 비교하여 하나의 1이 있을 때만 1을 반환한다. 즉, 1 ^ 0 은 1을 반환하지만 1 ^ 1은 0을 반환한다.
Shifting operators
Shifting 비트(<<, >>)를 다루는 두 개의 연산자가 있다. 추측할 수 있듯이 차이점은 숫자의 비트를 이동시킨다는 것이다.
<<: 숫자의 모든 비트를 왼쪽으로 n번 이동한다. 이동을 할 때 발생하는 빈 공간은 0으로 채워진다.>>: 숫자의 모든 비트를 오른쪽으로 n번 이동한다. 이 연산자는 양수 비트를 0으로 채우고 음수 비트를 1로 채운다.
보통 숫자의 첫 번째 비트가 기호를 나타내는데 사용이 된다. 1이면 음수 0이면 양수이다. 따라서 오른쪽 이동에서 위에 있는 추론은 우리가 이동하는 숫자의 부호를 유지하려고 저런식으로 작동하는 것이다.
Bit manipulation
이제 연산자가 하는 일을 알았으니 비트를 조작하기 위해 연산자를 활용하는 방법을 살펴보자.
마스킹(Masking)
마스킹이라는 것은 단순하게 간단한 문자열을 보내고 다른 숫자를 할당하여 플래그를 나타내는 방법이다. 일련의 예 또는 아니오 질문을 신속하게 요청하는 방법이다.
우리가 웹사이트를 가지고 있고 4개의 Flag가 있다고 가정을 해보자
- A : 유저권한인가?
- B : 올바른 지역에 있나?
- C : 아이스크림을 먹을 수 있나?
- D : 로봇인가?
이렇게 4개의 Flag가 있다고 생각하면 4자리의 이진문자열로 표현해서 보낼 수 있다.
0000 = DCBA
어떤 위치에 1을 넣으면 플래그를 변경할 수 있다.
- 1000 (binary) = Flag D = 8 (integer)
- 0100 (binary) = Flag C = 4 (integer)
- 0010 (binary) = Flag B = 2 (integer)
- 0001 (binary) = Flag A = 1 (integer)
이렇게 되면 한 번에 2가지 이상의 Flag의 변경이 가능하다.
- 1010 (binary) = Flag D and Flag B = 10 (integer)
- 0111 (binary) = Flag C, B and A = 7 (integer)
function changeFlag(binary){
const flagD = 8
const flagC = 4
const flagB = 2
const flagA = 1
let flags = []
if(binary & flagD){
flags.push("Change flagD")
}
if(binary & flagC){
flags.push("Change flagC")
}
if(binary & flagB){
flags.push("Change flagB")
}
if(binary & flagA){
flags.push("Change flagA")
}
return flags
}
// 최대는 15
changeFlag(8)
changeFlag(11)
changeFlag(1)
changeFlag(15)
Cheat Sheet
{kind=link}
| Operator | Usage | Description |
|---|---|---|
| Bitwise AND | a & b | 왼쪽 피연산자와 오른쪽 피연산자의 비트가 모두 1 인 경우 1을 반환한다. |
| Bitwise OR | a | b | 왼쪽 또는 오른쪽 피연산자의 비트가 하나인 경우 각 비트에서 하나를 반환한다. |
| Bitwise XOR | a ^ b | 왼쪽 피연산자와 오른쪽 피연산자 둘 다 아닌 경우 비트 위치의 1을 반환한다. |
| Bitwise NOT | ~a | 피연산자의 비트를 뒤집는다. |
| Left shift | a << b | a를 이진수 표현 b 비트를 왼쪽으로 shift하고 오른쪽에 0을 shift한다. |
| Sign-propagating right shift | a >> b | a를 이진수로 b 비트를 오른쪽으로 shift하고, 오른쪽으로 나온 비트를 제거한다. |
| Zero-fill right shift | a >>> b | a를 이진수로 b 비트를 오른쪽으로 shift하고, shift off 한 비트를 버리고, 왼쪽에서 0을 shift한다. |
Reference
- Programming with JS: Bitwise Operations
- JavaScript: Bitwise Operators
- Using JavaScript’s Bitwise Operators in Real Life
- Bitwise Operators in Javascript
- A Comprehensive Primer on Binary Computation and Bitwise Operators in Javascript

들어가기에 앞서 먼저 BOM에 대해서 알아보자.
당연하게 웹은 브라우저에서 돌아가기 때문에 웹 개발을 하다 보면 브라우저와 밀접한 관계를 가지게 된다. 브라우저와 관련된 객체들의 집합을 브라우저 객체 모델(BOM : Browser Object Model)이라고 부른다. BOM을 사용하면 창을 이동하고 상태 표시줄의 텍스트를 변경하는 페이지 내용과 직접 관련이 없는 브라우저와 관련된 기능을 사용할 수 있다. DOM은 이 BOM 중 하나이다.
예시)
history,location,navigator,screen
BOM의 최상위 객체는 window라는 객체이고, DOM은 window 객체의 하위 객체이다.

DOM이란?
문서 객체 모델(The Document Object Model(DOM)) 은 HTML, XML 문서의 프로그래밍 interface 이다. - MDN
HTML에는 <html>, <head>, <body>와 같은 많은 태그가 있는데 이를 JavaScript로 사용할 수 있도록 객체로 만들면 그것을 Document Object하고 한다.
DOM은 문서의 구조화된 표현을 제공하며 프로그래밍 언어(JavaScript 등)가 DOM 구조에 접근할 수 있는 방법을 제공하여 문서 구조, 스타일, 내용 등을 변경할 수 있도록 해준다.
DOM은 어떻게 생겼나?
DOM의 모양을 이해하는데 선행되는 자료구조는 Tree 구조이다. DOM이 바로 Tree 형식의 자료구조를 가지고 있기 때문이다.
이름 그대로 Tree 구조는 나무가 땅에서 솟아 위로 뻗어 나가면서 가지를 치면서 나가는 모양으로, DOM은 거꾸로 있는 모양이다.

DOM은...
- 문서의 구조화된 표현을 제공하며 프로그래밍 언어가 DOM 구조에 접근할 수 있는 방법을 제공한다.
- 문서 구조, 스타일, 내용 등을 변경할 수 있게 돕는다.
우리가 위와같이 조작을 할 수 있는 이유는 DOM API를 제공하기 때문이다. 아래의 사진은 Node 하위 구조를 보여주고 있다.
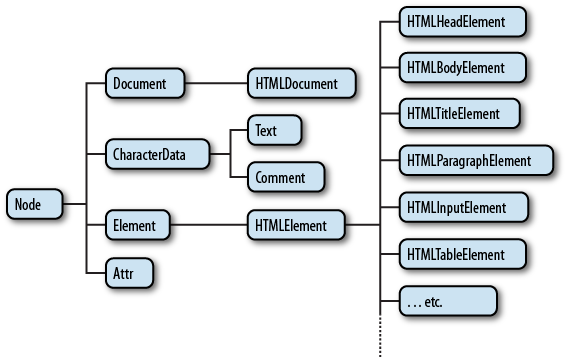
출처: http://www.stanford.edu/class/cs98si/slides/the-document-object-model.html
프로토타입 기반으로 본다면 아래와 같은 구조를 가진다.
Object < EventTarget < Node < DocumentType < <!DOCTYPE html>(ElementNode)
Object < EventTarget < Node < Element < HtmlElement < HtmlhtmlElement < html(ElementNode)
- 아래 코드와 같이 HTML Element Node는 상속(Object, EventTarget, Node, Element, HtmlElement, HTMLhtmlElement) 받은 모든 객체의 속성 및 메서드들을 사용할 수 있게 된다.
const html = document.querySelector('html');
console.log(html); // html
console.log(html.__proto__); // HTMLhtmlElement
console.log(html.__proto__.__proto__); // HtmlElement
console.log(html.__proto__.__proto__.__proto__); // Elemenet
console.log(html.__proto__.__proto__.__proto__.__proto__); // Node
console.log(html.__proto__.__proto__.__proto__.__proto__.__proto__); // EventTarget
console.log(html.__proto__.__proto__.__proto__.__proto__.__proto__.__proto__); // Object
DOM과 HTML 코드의 차이점
우리가 웹페이지를 만들 때 HTML을 작성한다. 그렇다면 우리가 작성하는 이 소스가 DOM과 똑같을까?
우리가 작성한 소스는 브라우저가 읽어서 DOM Tree를 만든다.
참고) Im-D/Dev-Docs 브라우저의 작동 원리
HTML 코드는 DOM과 똑같은 것으로 예상되지만 브라우저에서 생성한 DOM과는 엄연히 다르다. 예시로 우리가 작성한 코드 중 중대한 오류가 아닌 이상 브라우저가 자동으로 소스 코드의 오류를 수정한다. (Ex. tbody)


이외
- HTML 파일에 단어 하나라도 존재하더라도 브라우저는 이를
html과body으로 감싸고head를 필수적으로 추가한다.


- DOM을 생성하는 과정에서 여는 태그는 작성을 하고 닫는 태그를 작성하지 않는 경우 자동 생성하여 맞춰서 오류가 발생하지 않는다.


그렇다면 우리가 작성한 코드가 실제 DOM으로 만들어진 것을 어디서 볼 수 있나?
DevTools
우리가 브라우저로 소스를 열어서 F12버튼 또는 Ctrl + Shift + i를 누르게 되면 브라우저 DevTools이 나오게 된다.

Element Tab
Element가 실제로 그려진 DOM Tree를 볼 수 있는 곳으로 Element의 스타일 이벤트 등을 볼 수 있으며 실제로 조작을 하면서 변화를 확인해 볼 수 있다.
Console Tab
JavaScript를 사용해서 DOM을 조작할 수 있다. 실제로 JavaScript 엔진을 사용해서 테스트를 해보고 싶을 때 많이 사용하는 공간으로 IntelliSense를 보는 공간으로도 사용이 가능하다.
브라우저에서 테스트할 때 원하는 Element를 JavaScript로 찾기 힘들 때 Element Tab에서 해당 Element를 클릭 후 Console 창에서 $0으로 호출해서 바로 사용이 가능하다.
기본적으로 브라우저에서 클릭 된 history를 보관하고 있어 이전에 선택한 Element를 다시 가져올 수 있다.

Reference
- 무하프로젝트
- 힘내서 공부해보자
- introduction to the dom
- What’s the Document Object Model, and why you should know how to use it.
- What is the DOM?
- W3C: What is the Document Object Model?
- MDN: Introduction - Document Object Model
- Wikipedia: Document Object Model
Class
ES6에 Class 문법이 추가되었다. Class는 특별하게 새로 만들어진 것이 아니다. 기존에 존재하고 있던 상속과 생성자 함수를 기본으로 한 Proptotype의 syntactic sugar이다.
Class 문법이 나오기 전 사람들은 JavaScript를 OOP답게 사용하고 싶어 했다. 그래서 다양한 방법을 사용해서 구현했다.
Constructor Function
Class 문법이 생기기 전에는 JavaScript에서는 모든 것을 Function으로 만들어야 했다. 그래서 사람들이 Class처럼 사용하기 위해서 Constructor function을 사용해서 비슷하게 사용하였다.
function Vehicle(make, model, color) {
this.make = make,
this.model = model,
this.color = color,
this.getName = function () {
return this.make + " " + this.model;
}
}
위와 같이 함수를 선언함으로써 Java에서 사용하는 Class와는 모양새는 다르지만, Class에 좀 더 가까워졌다. 이제 우리는 Vehicle이라는 것을 선언했으니 인스턴스를 만들어보자
const car = new Vehicle("Toyota", "Corolla", "Black");
const car2 = new Vehicle("Honda", "Civic", "White");
위와 같이 new 키워드를 사용해서 인스턴스를 만들 수 있다.
그런데 문제가 있다.
새로운 Vehicle()을 만들 때 JavaScript 엔진은 두 객체의 각각에 대한 Vehicle Constructor 함수 사본을 만든다. 즉 각각의 인스턴스의 공간이 만들어지는 것이다. 또한 속성과 메소드는 Vehicle()의 모든 인스턴스에 복사가 된다.
이게 왜 문제가 되는가? 라고 생각할 수 있다. 제일 문제는 Constructor 함수의 멤버 함수(메서드)가 모든 객체에서 반복된다. 계속 똑같은 멤버 함수를 만드는 것이다. 이것은 매우 불필요하게 낭비를 하기 때문이다.
다른 문제는 기존의 만든 객체에 새로운 속성이나 메서드를 추가를 하지 못한다는 것이다.
car2.year = "2019"
위와 같이 추가를 하더라도 다른 인스턴스에는 새로운 속성이나 메서드는 따로따로 넣어주어야 한다.
function Vehicle(make, model, color, year) {
this.make = make,
this.model = model,
this.color = color,
this.year = year, // 위와 같이 추가를 해야한다.
this.getName = function () {
return this.make + " " + this.model;
}
}
Prototype
JavaScript는 내부적으로 새로운 함수가 만들어지면 엔진은 prototype이라는 기본 속성을 추가한다.

prototype 중 __proto__ 속성은 dunder proto 라고 불리고, Constructor 함수의 prototype 속성을 가리킨다.
생성자 함수의 새로운 인스턴스를 만들어질 때마다 dunder proto는 다른 속성, 메서드와 함께 인스턴스에 복사가 된다.

prototype 객체는 아래와 같이 Constructor 함수의 속성, 메서드를 추가 가능하며 Constructor 함수의 모든 인스턴스에서 사용할 수 있다.
car.prototype.year = "2019"

이 접근법에는 몇 가지 주의 사항이 있는데 prototype 속성과 메서드는 Constructor 함수의 모든 인스턴스와 공유를 한다. 만약 인스턴스의 하나가 기본 속성에서 변경했다면 모든 인스턴스가 아닌 해당 인스턴스에서만 변경이 된다.
다른 한 가지는 참조 유형 속성이 모든 인스턴스 간에 항상 공유된다. 하나의 인스턴스에서 수정하면 모든 인스턴스에 대해 수정이 된다.

Class
이제 Constructor 함수와 prototype에 대해 알아봤다. 이제 Class에 대해 알아보자. 위의 2개를 살펴봄으로써 좀 더 쉽게 이해할 수 있다. 이전의 것들과 크게 차이가 나는 것이 없기 때문이다.
JavaScript 클래스는 prototype 기능을 활용하여 Constructor 함수를 작성하는 새로운 방법일 뿐이다.(syntactic sugar)
class Vehicle {
constructor(make, model, color) {
this.make = make;
this.model = model;
this.color = color;
}
getName() {
return this.make + " " + this.model;
}
}
생성 방법은 위처럼 만들면 된다. 위와 동일하게 인스턴스를 생성해보면 동일하게 new 키워드를 사용하면 된다.
const car = new Vehicle("Toyota", "Corolla", "Black");
Class로 만든 것을 기존 방법으로 다시 작성한다면 아래와 같을 것이다.
function Vehicle(make, model, color) {
this.make = make;
this.model = model;
this.color = color;
}
Vehicle.prototype.getName = function () {
return this.make + " " + this.model;
}
const car = new Vehicle("Toyota", "Corolla", "Black");
이것은 Class가 Constructor 함수를 수행하는 새로운 방법이라는 것을 증명한다. 더욱 실제 Class와 비슷하게 만들기 위해서 도입된 몇 가지 규칙이 있다.
생성자가 작동하려면 new 키워드가 필요하다.
const car = new Vehicle("Toyota", "Corolla", "Black");
new를 사용하지 않고 만들 경우 아래와 같은 에러가 발생한다.
Class의 메서드는 non-enumerable 하다.
JavaScript에서 객체의 각 속성에는 해당 속성에 대해 enumerable flag 가 있다. Class는 prototype에 정의된 모든 메서드에 대해 이 flag를 false로 설정한다.
Class에 생성자를 추가하지 않으면 기본 빈 constructor()가 자동으로 추가된다.
constructor(){ }
Class 안의 코드는 항상 strict 모드 이다.
이것은 오류가 없는 코드를 작성하거나, 잘못된 입력 또는 코드 작성 중 구문 오류 또는 다른 곳에서 참조된 실수로 일부 코드를 제거하여 코드를 작성하는 데 도움을 준다.
Class는 호이스팅이 되지 않는다.

Class는 Constructor 함수나 객체 리터럴과 같은 속성 값 할당을 허용하지 않는다.
함수 또는 getter/setter 만 가질 수 있다. property:value 할당은 불가능하다.
Class Features
constructor
constructor는 Class 자체를 나타내는 함수 자체를 정의하는 Class 선언의 특수 함수이다. 인스턴스를 새로 만들면 constructor()가 자동으로 호출된다.
const car = new Vehicle("Honda", "Accord", "Purple"); // call constructor
constructor는 super 키워드를 사용하여 확장된 Class constructor를 호출할 수 있다.
하나 이상의 생성자 함수를 가질 수 없다.
Static Methods
Static Methods는 prototype 에 정의된 Calss의 다른 메서드와는 다르게 prototype이 아닌 Class 자체의 함수이다.
Static Methods는 static 키워드를 사용하여 선언하며 주로 유틸리티 함수를 만드는 데 사용된다. Class의 인스턴스를 만들지 않고 호출 가능하다.
class Vehicle {
constructor(make, model, color) {
this.make = make;
this.model = model;
this.color = color;
}
getName() {
return this.make + " " + this.model;
}
static getColor(v) {
return v.color;
}
}
let car = new Vehicle("Honda", "Accord", "Purple");
Vehicle.getColor(car); // "purple"
정적 메서드는 Class 인스턴스에서 호출할 수 없다.
Getter / Setter
getter/setter를 사용하여 속성값을 가져오거나 속성값을 설정할 수 있다.
class Vehicle {
constructor(model) {
this.model = model;
}
get model() {
return this._model;
}
set model(value) {
this._model = value;
}
}
getter/setter는 Class prototype에 정의된다.

Subclassing
Subclassing은 Javascript Class에서 상속을 구현할 수 있는 방법으로 extends 키워드는 Class의 하위 클래스를 만드는 방법이다.
class Vehicle {
constructor(make, model, color) {
this.make = make;
this.model = model;
this.color = color;
}
getName() {
return this.make + " " + this.model;
}
}
class Car extends Vehicle{
getName(){
return this.make + " " + this.model +" in child class.";
}
}
const car = new Car("Honda", "Accord", "Purple");
car.getName(); // "Honda Accord in child class."
getName()를 호출하면 자식클래스의 함수가 호출된다.
가끔 부모의 함수를 사용해야 할 때가 있다. 그럴 때는 super 키워드를 사용하면 된다.
class Car extends Vehicle{
getName(){
return super.getName() +" - called base class function from child class.";
}
}
- 옛날 방식인
prototype을 사용해서 상속 구현해보기
function Vehicle(make, model, color) {
this.make = make;
this.model = model;
this.color = color;
}
Vehicle.prototype.getName = function() {
return this.make + " " + this.model;
};
function Car(make, model, color) {
this.make = make;
this.model = model;
this.color = color;
}
Object.setPrototypeOf(Car, Vehicle);
Object.setPrototypeOf(Car.prototype, Vehicle.prototype);
Car.prototype.getName = function() {
return this.make + " " + this.model +" in child class.";
};
const vehicle = new Vehicle("Honda", "Accord", "Purple");
const car = new Car("Honda", "Accord", "Purple");
console.log(vehicle.getName()); // Honda Accord
console.log(car.getName()); // Honda Accord in child class.
팩토리 디자인 패턴 간단히 살펴보기
위의 코드를 아래와 같이 변경을 함으로써 new 키워드를 사용하지 않고 매번 새로운 객체를 만들어서 전달받는다.
const Vehicle = function(make, model, color){
const newVehicle = {};
newVehicle.make = make;
newVehicle.model = model;
newVehicle.color = color;
newVehicle.getName = function(){
return this.make + " " + this.model;
}
return newVehicle;
};
const vehicle = Vehicle("Honda", "Accord", "Purple");
console.log(vehicle.getName()) //Honda Accord
Reference
- Understanding Classes in JavaScript
- How ES6 classes really work and how to build your own
- Understand the Factory Design Pattern in plain JavaScript
- Javascript Classes — Under The Hood
this call apply bind
Function vs Method
한가지 예제를 살펴보고 console.log()가 어떻게 출력이 되는지 확인해보자.
// 함수
const greeting = () => {
console.log(this);
}
const module = {
greeting() {
console.log(this);
}
}
greeting(); // window object
module.greeting(); // module object
흔히 사람들이 실수하는 코드 중 하나이다.
여기서 제일 유심히 보아야 하는 것은 this가 다르다는 것이다. Java나 다른 언어에서의 this와는 다르게 작동하고 있다는 것은 확실하다.
this에 대한 더 많은 내용은 아래의 참고 글을 읽어보길 바란다.
function Module(name) {
this.name = name;
}
Module.prototype.getName = function() {
var changeName = function() {
console.log(this); // window
return this.name + '입니다.';
}
return changeName();
}
const module = new Module('sNyung');
console.log(module.getName());
위와 같이 메서드 내부에서 함수를 정의하고 this를 사용하게 되면 Module이라고 생각하지만 window를 바라보고 있다. 그리고 이걸 해결하는 방법은 흔히 self 또는 that을 사용해서 해결한다.
function Module(name) {
this.name = name;
}
Module.prototype.getName = function() {
const self = this;
// const that = this;
const changeName = function() {
console.log(self); // Module
return self.name + '입니다.';
}
return changeName();
}
const module = new Module('sNyung');
console.log(module.getName());
또는 ES6에서 추가가 된 화살표 함수(Arrow Function)를 사용해서 해결 가능하다.
function Module(name) {
this.name = name;
}
Module.prototype.getName = function() {
const changeName = () => {
console.log(this); // Module
return this.name + '입니다.';
}
return changeName();
}
const module = new Module('sNyung');
console.log(module.getName());
call()
자바스크립트에서 object를 효율적으로 사용하면서 재사용 패턴까지 구현할 수 있는 유용한 방법으로 Function.prototype.call() 함수가 있다.
call은 ES6에서 화살표 함수가 나오기 전 self 또는 that를 사용하지 않고 this까지 해결할 수 있는 방법이다.
function Module(name) {
this.name = name;
}
Module.prototype.getName = function() {
const changeName = function() {
console.log(this);
return this.name + '입니다.';
}
// return changeName.call(this, 1,2,3,4);
return changeName.call(this);
}
const module = new Module('sNyung');
console.log(module.getName());
call은 호출하는 즉시 Function을 실행시킨다.
fun.call(thisArg[, arg1[, arg2[, ...]]])
apply()
이번에는 call과 매우 유사한 apply를 보자.
function Module(name) {
this.name = name;
}
Module.prototype.getName = function() {
const changeName = function() {
console.log(this);
return this.name + '입니다.';
}
// return changeName.apply(this, [1,2,3,4]);
return changeName.apply(this);
}
const module = new Module('sNyung');
console.log(module.getName());
apply도 호출하는 즉시 Function을 실행시킨다.
fun.apply(thisArg, [argsArray])
call과 apply는 첫 번째 인자의 this를 내부 함수에서 사용할 this로 설정한다. apply는 call과 같이 첫 번째 인자로 this를 받는 건 똑같지만 뒤에 넘겨줄 값을 [1,2,3,4,5]처럼 배열 형태로 넘겨준다. (call과 같은 경우에는 1,2,3,4,5처럼 배열이 아닌 ,로 전달한다)
bind()
call과 apply는 내부 함수에서 사용할 this를 설정하고 함수 바로 실행까지 해주지만, bind는 this만 설정해주고 함수 실행은 하지 않고 함수를 반환한다.
function Module(name) {
this.name = name;
}
Module.prototype.getName = function() {
const changeName = function() {
console.log(this);
return this.name + '입니다.';
}
let bindChangeName = changeName.bind(this);
return bindChangeName();
}
const module = new Module('sNyung');
console.log(module.getName());
Reference
- https://blog.feruden.com/blog/call-apply-bind-in-javascript
- https://wayhome25.github.io/javascript/2017/02/18/js-oop-1/
Prototype
Javascript는 Proptotype기반의 언어라고 한다.
그렇다면 js를 공부한다면 알아야한다.
Javascript의 기본을 익힐때 Object, Function 이렇게 2가지를 먼저 생각하고 알고 있으면 된다.
새로운 function 생성
먼저 새로운 function을 생성한다고 가정하자.

// 기본 function 생성
function Animal(){
this.name = "동물";
}
프로토타입에 있어서 크게 2가지로 나누게 된다면
- function(생성자)
- prototype Object
prototype object는 말그대로 object이면서 인자로 가지고 있는 constructor는 object function을 가르킨다. 여기서 가르키는 functions이 1번의 function이다. function의 prototype은 prototype object를 가르키고 있다. 즉 서로를 바라보고 있다.
Function(생성자)
위에서 생성된 function은 생성자의 역할을 한다. 우리가 만약
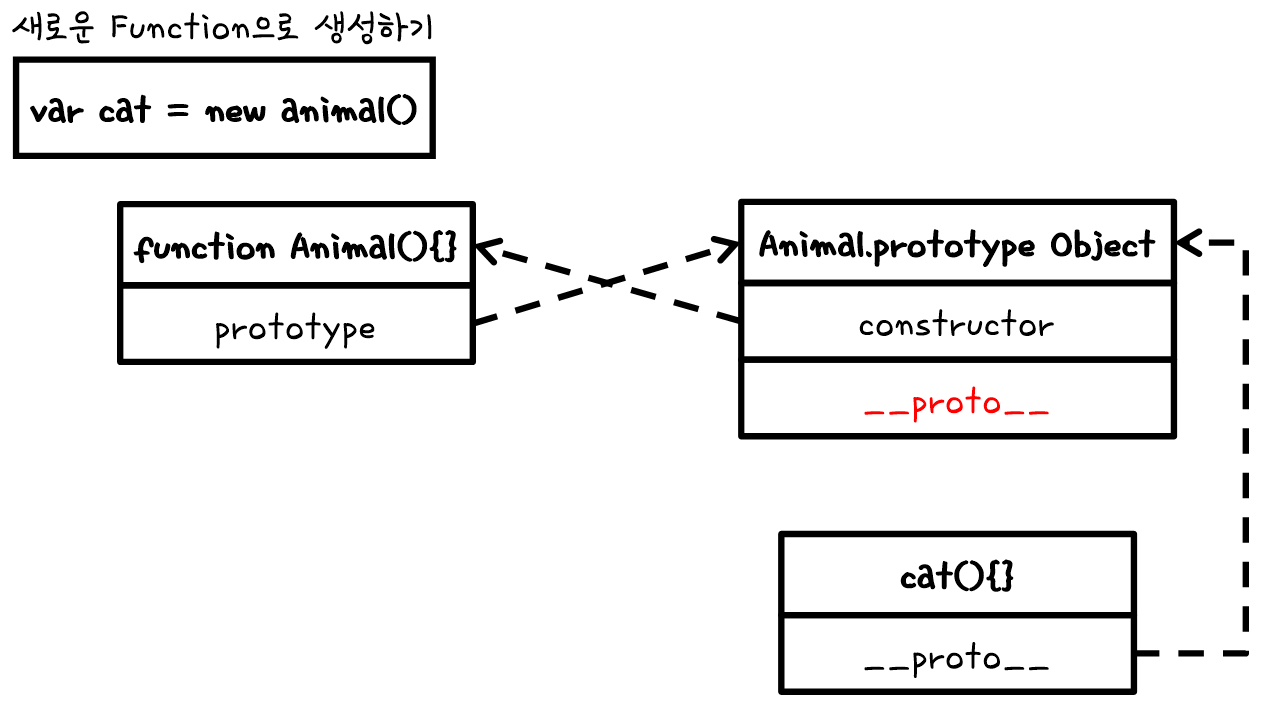
// cat 생성
var cat = new Animal();
위와 같이 고양이를 생성하게 된다면 function Animal인 생성자를 실행하는 것이다.
또한 function Animal안을 보게 되면 prototype이라는 인자가 있다. 이것은 Animal.prototype하고 연결이 되있는 것이다.
Prototype Object
그렇다면 이녀석?은 무엇일까?
기본적인 Animal의 prototype을 추가하게 되면 들어가는 객체이다.
추가적으로 constructor 역시 이 곳으로 들어가게 되고 function Animal하고 연결이 되어있어 생성을 한다면 여기의 생성자를 타게 된다.
Animal.prototype.constuctor / Animal(){this.name = "동물";}
이렇게 function Animal과 Animal.prototype(Object)를 서로 연결이 되어있다.
Prototype Link
[[Prototype]]], __proto__ 2개는 의미가 똑같다 그거 표기법이 다른 것이다.
그렇다면 위의 2개는 무엇일까:question:
먼저 위에서 생성한 cat을 살펴보면
cat
//result
//animal {name: "test"}
// name: "test"
// __proto__: Object
cat의 내역에는 당연하게 생성자로 생성된 name이 있다.
그런데 그 아래는?? 들어보지 못한 것이 하나 더 생겼다.
이것이 바로 Javascript에서 중요한 역할을 하게 된다.
cat.hasOwnProperty("name") //true
위의 예제를 보게 되면 나는 hasOwnPropert이런 함수를 생성한 적이 없다. 이 함수는 어디서 오게된 것일까:question:
바로 최상의 Object인 Object.prototype에서 온 것이다.
어떻게 해서 그것까지 갈 수가 있던걸까:question: 라고 생각할 수 있다.
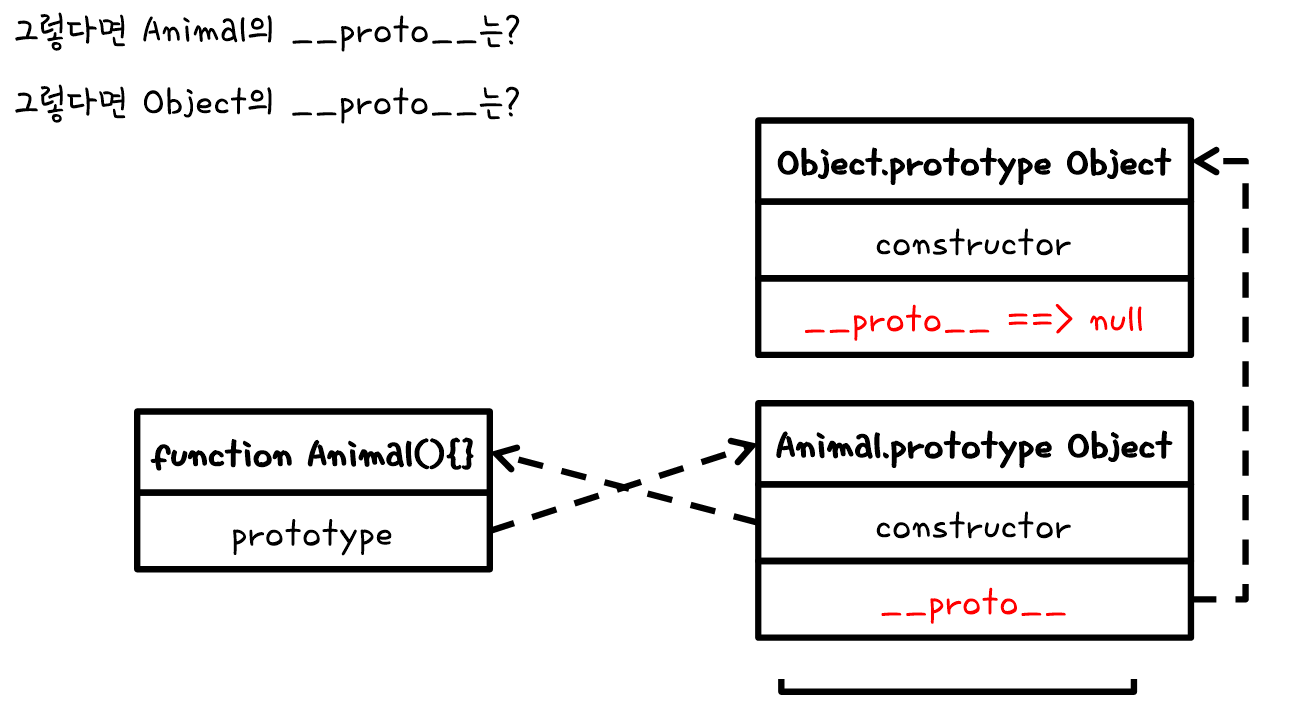
바로 그역할을 하는 것이 __proto__이다.
__proto__안을 보게 되면 constructor : Animal()이 있는 것을 볼 수 있다. 즉, cat을 생성한 function의 prototype이 __proto__에 연결이 되어 있다는 것을 알게 되는 것이다.
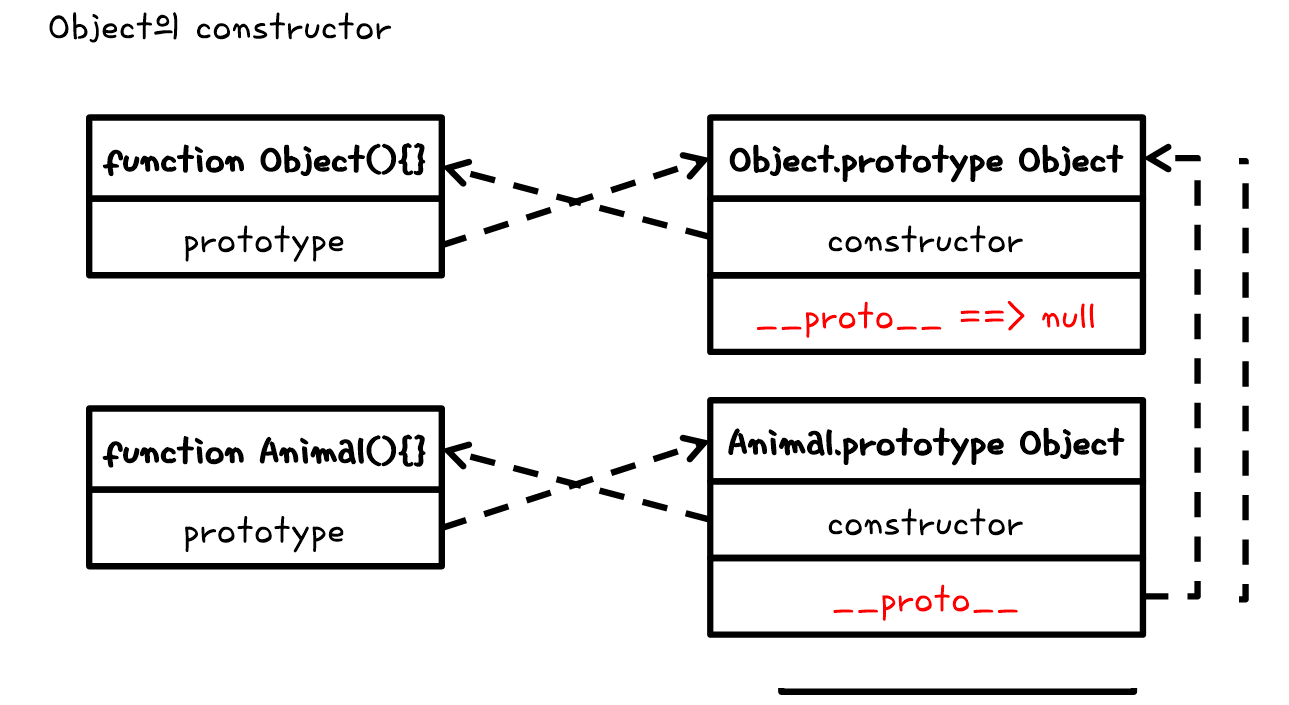
또한 Animal.prototype.__proto__에는 Object.prototype에 연결이 되어있다. 그리고 그 안에는 우리가 사용한 hasOwnPropert이 있어서 사용을 하는 것이다.
그렇다면 Object.prototype.__proto__는 무엇일까:question: 아무것도 없다. 그냥 null이 나온다. 모든 마지막은 Object.prototype에서 끝이 나는 것이다.
Object.prototype.__proto__ // null
참고
간단한 심화
심화적으로 최종적으로 Object로 모든것이 연결이 되는 것도 있지만 Object function.__proto__가 f(){}에 연결이 되어있다. f(){}의 constructor는 Function function이다.
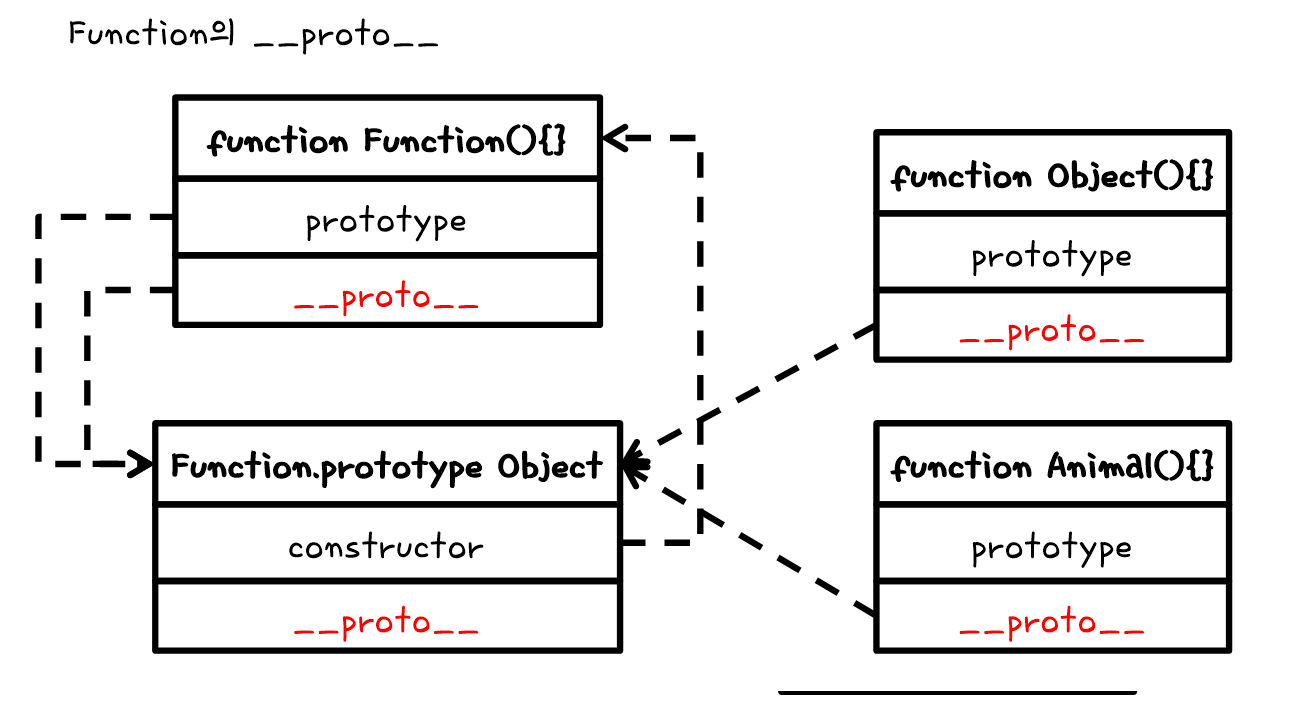
또한
Function.prototype Object의 __proto__는 Object.prototype Object에 연결이 되어있다.
즉,
이런걸로 봐서는 Function.prototype.__proto__는 당연히 객체임으로 최상위 Object.prototype에 연결이 되는 것이고, 추가적으론 Object function의 __proro__는 함수라고 생각을 하여 Function.prototype에 연결이 되는 것이다.
Object.create() & Object.assign()
Object.create()
Object.create(prototype_object, propertiesObject)
Object.create()는 기준이 되는 Object를 prototype으로 만들고 새로운 객체를 생성한다.
Object.create()는 주로 객체를 상속하기 위해 사용하는 메서드다. 첫 번째 인자를 상속하며, 두 번째 인자의 속성들을 추가로 구성한다.
두번째 인자 - 속성의 구성요소
공통의 구성요소는
configurable속성의 값을 변경할 수 있고, 삭제할 수도 있다면true로 설정한다. 기본값은false.enumerable속성이 대상 객체의 속성 열거 시 노출이 되게 하려면true로 설정한다. 기본값은false.
데이터 서술을 하는 데 사용되는 키는
value속성값. 아무 JavaScript 값(숫자, 객체, 함수 등)이나 가능하다. 기본값은undefinedwritable할당 연산자로 속성의 값을 바꿀 수 있다면true로 설정한다. 기본값은false.
접근자 서술을 하는 데 사용되는 키는
get속성 접근자로 사용할 함수, 접근자가 없다면undefined.- 속성에 접근하면 이 함수를 매개변수 없이 호출하고, 반환 값이 속성의 값이 된다. 이때
this값은 이 속성을 가진 객체=이다. 기본값은undefined.
- 속성에 접근하면 이 함수를 매개변수 없이 호출하고, 반환 값이 속성의 값이 된다. 이때
set속성 설정자로 사용할 함수, 설정자가 없다면undefined.- 속성에 값을 할당하면 이 함수를 하나의 매개변수로 호출한다. 이때
this값은 이 속성을 가진 객체이다. 기본값은undefined.
- 속성에 값을 할당하면 이 함수를 하나의 매개변수로 호출한다. 이때
Object.create()의 2번째 인자는 Object.defineProperties()를 따른다.
위의 구성요소는 이전에 사용하던 Object.defineProperties()에서 나오는 개념이다. 그 전에 Object.defineProperties()의 단일 설정 함수인 Object.defineProperty()를 살펴보자
Object.defineProperty()
Object.defineProperty()는 객체에 직접 새로운 속성을 정의하거나 이미 존재하는 속성을 수정한 후, 그 객체를 반환한다.
Object.defineProperty(obj, prop, descriptor)
obj: 속성을 정의할 객체.prop: 새로 정의하거나 수정하려는 속성의 이름 또는Symbol.descriptor: 새로 정의하거나 수정하려는 속성을 기술하는 객체.
아래의 예제는 자세히 보아야 한다. 여러 개념이 들어가 있는 예제이다.
const obj = {
age: 27,
country : 'seoul'
}
let oldCountry = 'Yongin'
console.log('init str', obj) // init str {age: 27, country: "seoul"}
const descriptor = {
enumerable: true,
configurable: true,
get: function(){
return '???'
},
set: function(value){
oldCountry = value
}
}
const newObj = Object.defineProperty(obj, 'country', descriptor) // 기존의 속성에서 새로운 속성을 정의
console.log('obj values => ',obj, obj.age, obj.country) // obj values => {age: 27} 27 ???
console.log('newObj values => ',newObj, newObj.age, newObj.country) // newObj values => {age: 27} 27 ???
console.log('oldCountry => ', oldCountry) // oldCountry => Yongin
newObj.age = 28
newObj.name = 'sNyung'
newObj.country = 'Re Seoul'
console.log('After newObj && obj values are => ', obj, obj.age, obj.country) // After newObj && obj values are => {age: 28, name: "sNyung"} 28 ???
console.log('oldCountry => ', oldCountry) // oldCountry => Re Seoul
Object.defineProperties()
Object.defineProperties(obj, props)
Object.defineProperty()의 복수 버전이다.
Object.defineProperties(obj, {
'property1': {
value: true,
writable: true
},
'property2': {
value: 'Hello',
writable: false
}
});
Object.create() - Sample 1
const prototypeObject = {
fullName: function(){
return this.firstName + " " + this.lastName
}
}
const person = Object.create(prototypeObject, {
'firstName': {
value: "sNyung",
writable: true,
enumerable: true
},
'lastName': {
value: "jo",
writable: true,
enumerable: true
}
})
console.log(person) // {firstName: "sNyung", lastName: "jo"}

New VS Object.create()
Object.create()와 new Constructor()는 꽤 비슷하지만, 다른 점이 있다. 다음은 이 둘의 차이를 보여주는 예제이다.
function Dog(){
this.pupper = 'Pupper';
};
Dog.prototype.pupperino = 'Pups.';
const maddie = new Dog();
const buddy = Object.create(Dog.prototype);
// Object.create()
console.log(buddy.pupper); // undefined
console.log(buddy.pupperino); // Pups.
// New
console.log(maddie.pupper); // Pupper
console.log(maddie.pupperino); // Pups.
성능상으로 new 생성자를 사용하는 것이 좋다고 한다. 확실히 성능 테스트를 해보면 알 수 있다.
성능 테스트
https://jsperf.com/snyung-new-vs-object-create
function Obj() {
this.p = 1;
}
Obj.prototype.chageP = function(){
this.p = 2
};
console.time('Object.create()');
var obj;
for (let i = 0; i < 10000; i++) {
obj = Object.create(propObj);
}
console.timeEnd('Object.create()');
// Object.create(): 약 12.994140625ms
console.time('constructor function');
var obj2;
for (let i = 0; i < 10000; i++) {
obj2 = new Obj();
}
console.timeEnd('constructor function');
// new: 약 2.379150390625ms
Polyfill
Object.create = (function () {
function obj() {};
return function (prototype, propertiesObject) {
// 첫 번째 인자를 상속하게 한다.
obj.prototype = prototype || {};
if (propertiesObject) {
// 두 번째 인자를 통해 속성을 정의한다.
Object.defineProperties(obj.prototype, propertiesObject);
}
return new obj();
};
})();
//--------------TEST---------------
const Vehicle = function(){
this.wheel = 4
}
Vehicle.prototype.getWheel = function() {
return this.wheel
}
const Motorcycle = Object.create(Vehicle.prototype, {'wheel': {value: 3, writable: true}});
console.log(Motorcycle)
Compat Table

Object.assign()
Object.assign() 메서드는 열거할 수 있는 하나 이상의 출처 객체로부터 대상 객체로 속성을 복사할 때 사용한다. 대상 객체를 반환한다.
target: 대상 객체.sources: 하나 이상의 출처 객체.
const obj = { a: 1 };
const copy = Object.assign({}, obj);
console.log(copy); // { a: 1 }
Object.assign()은 첫 번째 인자로 들어오는 target을 대상으로 두 번째 이후로 들어오는 인자를 병합할 때 사용한다.
예시
같은 properties가 들어올 경우 마지막에 들어온 값이 덮어쓰게 된다.
// app.js
let o1 = { a: 21, b: 22, c: 24 };
let o2 = { b: 23, c: 25 };
let o3 = { c: 26 };
let finalObj = Object.assign({}, o1, o2, o3);
console.log(finalObj); // {a: 21, b: 23, c: 26}
그러나 안타깝게도 Object.assign()는 ES6 문법의 Spread Operator가 나오면서 관심이 많이 줄어들게 되었다.
같은 기능을 포함하고 있는 ES6 문법의 Spread는 숙련도에 따라 다양하게 사용될 수 있다.
가장 많이 사용되는 기능 3가지를 포함하고 있는 예시를 보게 되면,
// Create Function with REST
const add = function(...arg){
console.log('arg', arg)
arg.map(e => console.log(e))
}
// Create Object
const obj = { a : 1, b : 2, c: 3, d: 4}
// Create Arr + Spread
const arr = ['a', ...Object.values(obj), 'b', 'c']
console.log(...arr)
add(...arr)
const {a,b, ...rest} = obj
console.log(a, b, rest)
위와 같이 ...은 사용 방법에 따라 다양하게 사용될 수 있다. 더 많은 기능을 찾아보기를 바란다.
Polyfill
Object.defineProperty(Object, "assign", {
value: function assign(target, varArgs) { // .length of function is 2
'use strict';
if (target == null) { // TypeError if undefined or null
throw new TypeError('Cannot convert undefined or null to object');
}
var to = Object(target);
for (var index = 1; index < arguments.length; index++) {
var nextSource = arguments[index];
if (nextSource != null) { // Skip over if undefined or null
for (var nextKey in nextSource) {
// Avoid bugs when hasOwnProperty is shadowed
if (Object.prototype.hasOwnProperty.call(nextSource, nextKey)) {
to[nextKey] = nextSource[nextKey];
}
}
}
}
return to;
},
writable: true,
configurable: true
});
Compat Table

Reference
- Object.create() - MDN
- Object.create in JavaScript
- Object.create(): the New Way to Create Objects in JavaScript
- Basic Inheritance with Object.create
- Understanding the difference between Object.create() and the new operator.
- JavaScript Object Creation: Patterns and Best Practices
- object-create.md - wonism
- Object.assign() = MDN
Map Filter Reduce
함수형 프로그래밍의 주요 기능 중 하나는 리스트와 리스트 연산자의 사용이다.
Javascript에는 초기 리스트에서 제공하는 모든 함수를 map, filter, reduce를 사용하여 원본 리스트는 그대로 유지하면서 다른 것으로 변환가능하다.
Map
구문
arr.map(callback(currentValue[, index[, array]])[, thisArg])
map() 메서드는 콜백함수를 적용하고 나오는 결과물을 가지고 새로운 배열로 반환한다.
객체 리스트에서 우리가 원하는 속성을 추가, 수정하는데 사용한다.
map은 callback을 인자로 받는다. 이 calllback은 iteration의 현재 값을 받으며 인덱스와 원본 배열도 같이 불린다.
optional하게 두 번째 인자로는 callback 내부에서 사용될 this를 바인딩한다.
V8 엔진 내부적으로 두번째 인자를 가지고
fn.call(secondArg, ...)를 사용하여 바인딩하고 있다.
Example
const numbers = [2, 4, 8, 10];
const halves = numbers.map(x => x / 2);
// halves is [1, 2, 4, 5]
pollyfill 만들어보기
Array.prototype.map = function (fn) {
var args
if(this == null){
return new TypeError("this is null or not defined")
}
var o = Object(this)
var len = o.length >>> 0;
if(typeof fn !== 'function'){
return new TypeError(fn, " is not a functions")
}
var arr = new Array(len)
/* 추가적으로 들어오는 argument 처리 */
if (arguments.length > 1) {
args = arguments[1];
}
var n = 0;
while (n < len){
if (n in o) {
arr[n] = fn.call(args, o[n], n, o)
n++
}
}
return arr
}

Filter
arr.filter(callback(element[, index[, array]])[, thisArg])
주어진 함수에 대해서 조건을 통과한 요소들을 가지고 새로운 배열을 만들어서 반환하는 메서드.
filter는 map과 같은 arguments를 받는다. filter에서는 return 값으로 true나 false를 반환하면 된다. true를 반환하면 배열에 추가하며, false를 반환하면 추가하지 않는다.
결국, 새로운 배열이 나오되 true로 반환된 요소만 담겨서 나오게 된다.
const words = ["spray", "limit", "elite", "exuberant", "destruction", "present"];
const longWords = words.filter(word => word.length > 6);
// longWords is ["exuberant", "destruction", "present"]
pollyfill 만들어보기
Array.prototype.filter = function (fn) {
var args
if(this == null){
return new TypeError("this is null or not defined")
}
var o = Object(this)
var len = o.length >>> 0;
if(typeof fn !== 'function'){
return new TypeError(fn, " is not a functions")
}
var arr = new Array(len)
if (arguments.length > 1) {
args = arguments[1];
}
var n = 0;
var i = -1;
while (++i !== len){
if (n in o) {
if(fn.call(args, o[i], i, o)){
arr[n++] = o[i]
}
}
}
arr.length = n
return arr
}

Reduce
arr.reduce(callback[, initialValue])
reduce() 메서드는 accumulator와 배열의 각 요소(왼쪽에서 오른쪽으로)에 대해 함수를 적용하여 단일 값으로 반환한다.
map, filter와 비슷하지만, callback argument가 다르다. callback은 accumulator를 받는다. 이 값은 이전에 누적된 반환값으로 현재 값, 현재 인덱스, 원본 배열을 같이 받는다.
const total = [0, 1, 2, 3].reduce((sum, value) => sum + value, 1);
// total is 7
pollyfill 만들어보기
Array.prototype.reduce = function (fn) {
var args;
if(this == null){
return new TypeError("this is null or not defined");
}
var o = Object(this);
var len = o.length >>> 0;
if(typeof fn !== 'function'){
return new TypeError(fn, " is not a functions");
}
var n = 0;
var value;
/* 추가적으로 들어오는 argument 처리 */
if (arguments.length > 1) {
value = arguments[1];
}else{
while (n < len && !(n in o)) {
n++;
}
if (n >= len) {
throw new TypeError( 'Reduce of empty array with no initial value' );
}
value = o[n++];
}
while (n < len){
if (n in o) {
value = fn(value, o[n], n, o);
}
n++;
}
return value
}

Reference
순수함수, 부수효과(사이드이펙트), 상태변이
SPA 프레임워크를 사용하다보면 함수형, 안전한 동시성 측면에서 순수함수는 필수적이다.
순수함수가 무엇인지 다루기 전에 함수를 자세히 살펴보는 것이 좋다. 함수형 프로그래밍을 이해하기 쉽게 만들 수 있다.
함수란?
함수는 인수라고하는 입력을 받아 반환값이라는 출력을 생성하는 프로세스이다.
- Mapping : 주어진 입력을 기반으로 일부 출력을 생성한다. 함수는 입력값을 출력값에 매핑한다.
- Procedures : 일련의 단계를 수행하기 위해 함수가 호출될 수 있다. 시퀀스는 프로시저라고 하며, 스타일의 프로그래밍을 절차 프로그래밍이라고 한다.
- I/O : 대개 함수는 화면, Storage, 시스템 로그 또는 네트워크와 같은 시스템의 다른 부분과 통신하기 위한 기능이 있다.
Mapping
순수함수는 모두 매핑에 관한 것이다. 함수는 입력 인수를 반환값과 매핑한다. 즉, 각각 입력 집합에 대해 출력이 존재한다. 함수는 입력을 받아 해당 출력을 반환한다.
Math.max는 인수들 중에서 가장 큰 수를 반환한다.
Math.max(2, 8, 5); // 8
예를 들어 위와 같이 2, 8, 5이 들어간다. Math.max는 많은 수의 인수를 취하여 가장 큰 인수값을 반환하는 함수이다. 이 경우에 전달된 가장 큰 숫자는 8이면서 반환값이다.
함수는 컴퓨팅과 수학에서 정말로 중요하다. 유용한 방법으로 데이터를 처리하는데 도움이 된다. 훌륭한 프로그래머는 함수를 설명하는 이름을 지정하여 코드를 볼 때 함수 이름을 보고 함수의 기능을 이해할 수 있다.
수학에도 함수가 있으며 Javascript의 함수의 매우 유사하게 작동한다.
f(x) = 2x
f라는 함수를 선언하고 x라는 인수를 사용하고 x에 2를 곱한다. 이 함수를 사용하려면 간단히 x값을 제공하면 된다.
f(2)
대수학에서 이것은 쓰기와 정확히 같은 의미이다.
4
따라서 f(2)라 표시된 곳은 4로 대체할 수 있다.
이제 해당 함수를 JavaScript로 변환해보자.
const double = x => x * 2;
console.log()을 사용하여 함수의 출력을 검사할 수 있다.
console.log( double(5) ); // 10
수학함수에서 f(2)를 4로 바꿀 수 있다고 말했다. 이 경우 JavaScript엔진은 double(5)를 10으로 대체한다. double()은 순수함수이다.
순수함수
순수함수란 아래의 의미를 가진다.
- 동일한 입력이 주어지면 항상 동일한 출력을 반환한다.
- 사이드이펙트가 없다.
순수함수를 사용하여 프로그램 요구사항을 구현하는 것이 실용적이라면 다른 선택사항보다 더더욱 사용해야한다. 순수함수는 입력을 받아 해당 입력에 따라 출력을 반환한다. 프로그램에서 재사용 가능한 가장 간단한 코드 블록으로 컴퓨터 과학에서 가장 중요한 디자인 원칙 KISS(Keep It Simple, Stupid) 일 것이다.
순수함수는 외부상태와 완전히 독립적이므로 공유가능한 변경 가능한 상태와 관련된 버그의 전체 클래스에 영향을 받지 않는다. 또한 독립적인 특성으로 인해 많은 CPU 및 전체 분산 컴퓨팅 클러스터에서 병렬처리를 수행할 수 있는 훌륭한 후보가 되므로 많은 과학 및 리소스 집약적 컴퓨팅 작업에 필수적이다.
순수함수는 코드에서 쉽게 이동하고, 리팩토링하고, 재구성하기가 매우 독립적이므로 프로그램을 보다 유연하고 향후 변경에 적용할 수 있다.
공유상태의 문제점
모든 종류의 비동기 작업 또는 동시성으로 인해 유사한 경쟁 조건이 발생할 수 있다. 출력이 제어할 수 없는 이벤트 시퀀스에 의존하는 경우 경쟁조건이 발생한다. 실제로 공유 상태를 사용하고 있고, 그 상태가 모든 의도와 목적으로 결정적 요인에 따라 달라지는 시퀀스에 의존하는 경우 출력을 예측할 수 없으므로 제대로 테스트하거나 완전히 이해하는 것이 불가능하다.
JS가 단일 스레드에서 실행되므로 병렬 처리 문제에 영향을 받지 않으므로 괜찮다고 생각할 수 도 있지만, AJAX 예제에서 알 수 있듯이 단일 스레드 JS엔진은 동시성이 없음을 의미하지는 않는다. 반대로 JavaScript에는 많은 동시성 소스가 있다. API I/O, 이벤트 리스너, 웹 워커, iframe 및 시간초과는 모두 프로그램에 불확실성을 유발할 수 있다. 이것이 공유 상태와 결합하게 되면 버그를 만들어 낼 수 있다.
순수함수를 사용하면 이러한 버그를 피할 수 있다.
동일한 입력이 주어지면, 항상 같은 출력을 반환
double() 함수를 사용하면 함수 호출을 결과로 대체할 수 있으며 프로그램은 동일한 것을 의미한다. double(5)는 상관없이 프로그램에서 항상 10과 동일한 것을 의미한다. 아무리 해도 동일할 것이다.
그러나 모든 함수에 대해 똑같은 것을 말할 수는 없다. 일부 함수는 결과를 생성하기 위해 전달하는 인수 이외의 정보에 의존한다.
Math.random(); // => 0.4011148700956255
Math.random(); // => 0.8533405303023756
Math.random(); // => 0.3550692005082965
함수 호출에 인수를 전달하지는 않았지만 모두 다른 출력을 생성했다. 이는 Math.random ()는 순수하지 않다는 것을 의미한다. Math.random()은 실행할 때마다 0에서 1사이의 새로운 난수를 생성하므로 프로그램의 의미를 변경하지 않고 0.4011148700956255로 대체 할 수 없다.
함수는 동일한 입력이 주어지면 항상 동일한 출력을 생성하는 경우에만 순수하다. 대수학 클래스에서 이 규칙을 기억할 있다. 동일한 입력값이 항상 동일한 출력 값에 매핑된다. 그러나 많은 입력값이 동일한 출력값에 매핑될 수 있다.
예를 들어 다음 기능은 순수하다.
const highpass = (cutoff, value) => value >= cutoff;
동일한 입력 값은 항상 동일한 출력 값에 매핑됩니다.
highpass(5, 5); // => true
highpass(5, 5); // => true
highpass(5, 5); // => true
많은 입력 값이 동일한 출력 값에 매핑 될 수 있습니다.
highpass(5, 123); // true
highpass(5, 6); // true
highpass(5, 18); // true
highpass(5, 1); // false
highpass(5, 3); // false
highpass(5, 4); // false
순수함수는 더이상 결정적이거나 참조저긍로 투명하지 않기 때문에 외부 변경가능 상태에 의존해서는 안된다.
순수함수는 사이드이펙트가 없다.
순수함수는 사이트이펙트를 일으키지 않으므로 외부 상태를 변경할 수 없다.
불변성
JavaScript의 객체 인수는 참조이다. 즉, 함수가 객체 또는 배열 매개변수의 속성르 변경하는 경우 함수 외부에서 액세스 할 수 있는 상태가 변경된다. 순수함수는 외부 상태를 변경해서는 안된다.
순수함수는 결정론적이다.
항상 같은 입력하면 해당 함수는 같은 결과를 출력한다.
const add = (x, y) => x + y // A pure function
add는 출력이 전적으로 인수에 의존하기 때문에 순수함수이다. 결국 동일한 값을 지정하게 되면 동일한 출력을 생성한다.
그렇다면 아래와 같다면?
const magicLetter = '*'
const createMagicPhrase = (phrase) => `${magicLetter}abra${phrase}`
위와 같은 함수가 있다면 해당 점위 외부의 값에 따라 달라지게 된다. 그러므로 이는 순수함수라 할 수 없다.
불순수함수
const fetchLoginToken = externalAPI.getUserToken
위와 같은 함수는 어떠한가? 순수함수라 할 수 있을까? 전혀 그렇지 않을 것이다. 어떤 때는 잘 내려고 어떤때는 500 error를 내릴 수도 있다. 하물며 이 호출이 deprecated가 될 수도 있는 것이다.
따라서 이 함수는 결정적이지 않기 때문에 불순수함수라 할 수 있다.
순수함수는 사이드이펙트를 일으키지 않는다.
사이드이펙드란 외부 세계에서 관찰할 수 있는 시스템의 모든 변경을 말한다.
const calculateBill = (sumOfCart, tax) => sumOfCart * tax
calculateBill는 순수한가? 이에 필요한 특징이 2가지가 있다고 설명했었다.
- 함수는 결과를 생성하기 위해 인수에만 의존한다.
- 함수는 사이드이펙트를 발생시키지 않는다.
사이트이펙트에는 아래의 내용이 가이드에 포함되지만 이외에도 있을 수 있다.
- 파일시스템 변경
- 데이터베이스에 기록
- http call
- 데이터 변경
- 화면 그리기 / 로깅 / console
- 사용자 입력
- DOM 쿼리
- 시스템 상태에 접근
Math.random()- Getting the current time
사이드이펙트 자체를 나쁘게 보아서는 안된다. 실제로 종종 쓰이기 때문이다. 단 함수를 순수하게 선언하려면 어떤 것도 포함해서는 안된다. 모든 기능이 순수하거나 순수해야하는 것은 아니다.
왜 함수는 순수해야하나?
- 가독성
사이드이펙트로 인해서 읽기에 어려움이 따른다. 순수하지 않은 함수는 결정적이지 않으므로 주어진 입력에 대해 여러가지 다른 값을 반환할 수 있다.
우리는 다양한 가능성을 설명해야하는 코드를 작성하게 된다.
이 스니핏은 다양한 방법으로 실패할 수 있다. getTokenFromServer에 전달된 ID가 유효하지 않는 경우 어떻게 해야하나? 서버에 예상 토큰대신 충돌하여 오류를 반환한 경우 어떻게 해야하나
또한 순수함수는 문맥없이 읽기 쉽다. 필요한 모든 매개 변수를 미리 수신하고 응용프로그램의 상태와 대화 / 변조하지 않는다.
- 테스트 용이
순수함수는 본질적으로 결정론적이어서 단위 테스트를 작성하는 것이 휠씬 간단하다.
- 병렬 코드
순수함수는 입력에만 의존하고 부작용을 일으키지 않기 때문에 병렬 스레드가 실행되고 공유메모리를 사용하는 시나리오에 적합하다.
- 모듈성과 재사용성
순수함수를 작은 논리단위로 생각해야한다. 입력에만 의존하기 때문에 코드베이스의 다른 부분이나 다른 프로젝트 사이의 기능을 쉽게 재사용할 수 있다.
- 참조 투명성
간단히 말해서 참조 투명성은 프로그램의 전체 동작을 변경하지 않고 함수 호출을 출력값으로 대체할 수 있을을 의미한다.
순수함수는 많은 이점이 제공되지만 응용프로그램에 순수한 기능만 있는 것은 현실적이지 못한다.
그러나 우리의 응용프로그램에 적용하면 사이드이펙트가 없어서 외부세계에 관찰이 가능한 영향을 미치지 않는다. 대신 우리는 모든 부작용을 코드베이스의 특정부분에 캡슐화하려고 한다. 이렇게 하면 순수한 함수에 대한 단위 테스트를 작성하고 작동한다는 것을 알면 앱에서 문제가 발생하면 추적하기가 쉬워진다.
JavaScript에서 순수함수가 중요한 이유
함수형 프로그래밍에는 순수함수가 많이 사용된다. 또한 ReactJS 및 Redux와 같은 라이브러리에는 순수함수를 사용해야한다. 그러나 순수함수는 단일 프로그래밍 패러다임에 의존하지 않는 일반 Javascript에서도 사용할 수 있다. 순수한 기능과 불순한 기능을 혼합하여 사용할 수 있다.
모든 기능이 순수하거나 순수해야하는 것은 아니다. 예를 들어, DOM을 조작하는 버튼 누름에 대한 이벤트 핸들러는 순수한 기능에 적합지 않다. 그러나 이벤트 핸들러는 다른 순수한수를 호출하여 애플리케이션의 불완전한 함수를 줄일 수 있다.
테스트 가능성 및 리팩토링
가능한 경우 순수함수를 사용하는 또 다른 이유는 테스트와 리팩토링이다.
순수함수를 사용하면 얻을 수 있는 이점 중 하나는 즉시 테스트 할 수 있다는 것이다. 동일한 결과를 생성한다.
코드 유지 관리 및 리팩토링이 휠씬 쉬워지낟. 순수함수를 변경할 수 있으며 의동하지 않은 사이드이펙트를 변경할 수 있으며 의도하지 않는 부가용으로 인해 전체 응용프로그램이 엉망이 되어 지옥을 디버깅할 필요가 없다.
올바르게 사용하면 순수한 기능을 사용하면 더 나은 품질의 코드가 생성된다.
부록 - 관찰 가능한 사이트이펙트란?
관찰 가능한 사이드이펙트는 기능 내에서 외부 세계와의 상호작용이다. 함수 외부에 존재하는 변수를 변경하거나 함수 내에서 다른 메소드 호출까지 가능하다. 순수함수가 순수함수를 호출하는 경우 사이드이펙드가 아니며 호출한 함수는 여전히 순수하다.
Reference
JavaScript란?
JavaScript(JS)는 가벼운 인터프리터형, JIT-컴파일형 프로그래밍 언어, first-class functions를 지원한다.
주로 웹 페이지를 위한 스크립팅 언어로 알려졌지만, Node.js, Apache CouchDB, Adobe Acrobat처럼 많은 비 브라우저 환경에서도 사용된다.
JavaScript는 프로토타입 기반의 다중 패러다임 스크립팅 언어로서, 역동적이고, 객체지향형, 명령형 및 선언형(가령 함수형 프로그래밍) 스타일을 지원한다.
이 문서는 JavaScript 언어 자체만 다루며 웹 페이지를 비롯한 다른 사용 환경에 대해서는 다루지 않는다. 웹 페이지의 특정 API에 대하여 알고 싶다면 웹 API와 DOM을 참고하면 됩니다.
JavaScript의 표준은 ECMAScript입니다.
2012년 기준 최신 브라우저는 모두 ECMAScript 5.1을 전부 지원한다.
이전 브라우저의 경우는 최소한 ECMAScript 3까지 지원한다.
2015년 6월 17일 ECMA International에서는 ㄴ공식명 ECMAScript 2015로 불리는 ECMAScript의 6번째 주 버전을 발표했다(ECMAScript 6 혹은 ES6).
그 이후 ECMAScript 표준은 출시가 1년 주기이다.
JavaScript를 Java 프로그래밍 언어와 혼동해서는 안된다.
"Java"와 "JavaScript" 두 가지 모두 Oracle이 미국 및 기타 국가에 등록한 상표이다. 하지만, 두 언어는 문법 체계와 사용방법이 전혀 다릅니다.
Reference
ES3
ECMA-262-3 Execution Contexts
도입
오늘은 ECMAScript의 실행 컨텍스트와 이와 관련된 코드 유형에 대해 알아보자.
정의
Control이 ECMAScript 실행 코드로 이동될 때마다, Control은 실행 컨텍스트으로 들어가게 된다.
실행 컨텍스트(EC)는 ECMA-262 specification(사양)에서 실행 코드의 유형화와 차별화를 위해 사용하는 추상적인 개념이다.
이러한 표준은 기술적인 구현 관점에서 정확한 EC의 구조와 종류를 정의하지 않았다. 이는 결국 표준을 구현하는 ECMAScript 엔진에 달렸다.
논리적으로, 활성 실행 컨텍스트 집합은 stack으로 형성된다. 이 stack의 맨 아래에는 항상 global context가 있고, 가장 위에는 현재(활성) 실행 컨텍스트가 있다. 다양한 종류의 EC가 드나드는 동안 stack이 수정된다. (pulled/poped)
실행 코드 종류
실행 컨텍스트의 추상 개념으로 실행 코드 유형의 개념과 관련 있다. 코드 유형에 대해 말하면 특정 순간의 실행 컨텍스트를 의미할 수 있다.
예를 들어, 실행 컨텍스트 stack을 배열로 정의해보자.
ECStack = [];
함수가 재귀적으로 또는 생성자로 호출되더라도 함수 안으로 들어갈 때마다 stack에 push 한다. 내장 eval 함수 작업에서도 동일하다.
Global code
이 유형의 코드는 Program 수준에서 처리된다. 즉, 로드된 외부 .js 파일 또는 로컬 인라인 코드(<script></script> 태그 내부)이다. Global code는 함수 본문에 있는 코드 부분은 포함되어 있지 않다.
초기화(프로그램 시작)시 ECStack은 다음과 같이 된다.
ECStack = [
globalContext
];
Function code
Function code (모든 종류의 함수) 안으로 들어가게 되면, ECStack에 새로운 요소가 추가된다. concrete Function의 Code에는 내부 Function Code가 포함되어 있지 않다.
예를 들어, 한 번 재귀적으로 호출하는 함수를 보자.
(function foo(flag) {
if (flag) {
return;
}
foo(true);
})(false);
그러면 ECStack이 다음과 같이 바뀌게 된다.
// first activation of foo
ECStack = [
<foo> functionContext
globalContext
];
// recursive activation of foo
ECStack = [
<foo> functionContext – recursively
<foo> functionContext
globalContext
];
함수에서 모든 리턴은 현재 실행 컨텍스트를 종료하면, ECStack은 stack의 구현에 따라 연속적으로 거꾸로 꺼내진다. 해당 코드의 작업이 완료되면, ECStack은 프로그램이 종료될 때까지 globalContext만 가지고 있다.
Throw 되었지만, catch 되지 않은 예외는 하나 이상의 실행 컨텍스트를 종료할 수 있다.
(function foo() {
(function bar() {
throw 'Exit from bar and foo contexts';
})();
})();
Eval code
eval 코드는 매우 흥미롭다. 이 경우 calling context의 개념, 즉 eval 함수가 호출된 컨텍스트가 있다.
변수 또는 함수 정의와 같이 eval에 의해 수행된 작업은 calling context에 영향을 준다.
// influence global context
eval('var x = 10');
(function foo() {
// and here, variable "y" is
// created in the local context
// of "foo" function
eval('var y = 20');
})();
alert(x); // 10
alert(y); // "y" is not defined
Note: ES5의 strict-mode에서
eval은 이미 호출 컨텍스트에 영향을 미치지 않지만 대신 로컬 sandbox의 코드를 평가한다.
위의 예에서는 다음과 같은 ECStack 수정 사항이 있다.
ECStack = [
globalContext
];
// eval('var x = 10');
ECStack.push({
context: evalContext,
callingContext: globalContext
});
// eval exited context
ECStack.pop();
// foo funciton call
ECStack.push(<foo> functionContext);
// eval('var y = 20');
ECStack.push({
context: evalContext,
callingContext: <foo> functionContext
});
// return from eval
ECStack.pop();
// return from foo
ECStack.pop();
아주 캐주얼하고 논리적인 call-stack이다.
Note: 예전 SpiderMonkey(Firefox)에서 버전 1.7까지는
eval함수의 두 번째 인수로 전달할 수 있었다. 따라서 컨텍스트가 여전히 존재하면 개인 변수에 영향을 줄 수 있었다.
function foo() {
var x = 1;
return function () { alert(x); };
};
var bar = foo();
bar(); // 1
eval('x = 2', bar); // pass context, influence internal var "x"
하지만 최신 엔진에서는 보안상의 이유로 수정되어 더 이상 신경쓰지 않아도 된다.
Reference
ECMA-262-3 This
실행컨텍스트 선행이 필요합니다.
이번 주제는 this 키워드이다.
이 주제는 상당히 어려워서 종종 다른 실행 컨텍스트의 this 값을 처리할 때 이슈를 만들곤 한다.
정의
this는 실행 컨텍스트의 프로퍼티다.
activeExecutionContext = {
VO: {...},
this: thisValue // 다른 하나가 더 있다. scope, 총 3개로 구성되어 있다.
};
여기의 VO 는 변수 객체(Variable object)를 의미 한다.
this 는 컨텍스트의 실행 코드 타입과 직접적인 관련이 있다.
이 값은 컨텍스트로 진입하는 과정에서 정해지며, 컨텍스트 안의 코드가 실행 중에는 변하지 않는다.
좀 더 자세하게 들여다보자.
전역 코드 안의 this(This value in the global code) 이건 정말 단순하다. 전역이니까 당연히 this 는 전역객체 자신(global 또는 window) 이 될 것이다.
// 명시적인 전역 객체 프로퍼티 정의
this.a = 10; // global.a = 10
alert(a); // 10
// 규정되지 않은 식별자 할당을 이용한 암묵적 정의
b = 20;
alert(this.b); // 20
// 전역 컨텍스트의 변수 객체는 전역 객체 자신이기 때문에
// 또한 변수 선언을 이용한 암묵적 정의도 가능하다.
var c = 30;
alert(this.c); // 30
함수 코드 안의 this(This value in the function code) 이제부터가 진짜라고 할 수 있다. 함수타입의 코드의 this 는 함수에 정적으로 바인딩이 되지 않는다는 것이다.
컨텍스트로 들어갈 때 정해지며, 함수코드의 this 는 매번 바뀔 수 있다.
그러나 코드나 코드가 실행되고 this 는 변경이 이루어질 수 없다(이 얘기는 아래에서 또 나온다.).
즉 this를 재할당하는 것이 불가능하다는 것이다.
var foo = {x: 10};
var bar = {
x: 20,
test: function () {
alert(this === bar);
// true
alert(this.x); // 20
this = foo; // 에러, this 값을 변경할 수 없다.
alert(this.x); //
// 만약 위에서 에러가 나지 않았다면 20이 아닌 10이 출력될 것이다.
}
};
// 컨텍스트로 들어올 때 this가 가리키는 대상이 bar 객체로 결정된다.
// 왜 그러한지는 아래에서 자세하게 설명하겠다.
bar.test(); // true, 20
foo.test = bar.test;
// 그러나 여기의 this는 이제 foo를 참조할 것이다.
// 심지어 같은 함수를 호출하는 데도 말이다.
foo.test(); // false, 10
그렇다면 어떻게 해야 this가 바뀌는 것일까?
컨텍스트의 코드를 활성화한 호출자(caller)에 의해 제공된다.
즉 함수를 호출한 부모 컨텍스트가 존재한다는 것이다. 어떤 컨텍스트의 this가 참조하는 값을 어려움 없이 알아내기를 원한다면 중요한 이 부분을 이해하고 기억해야 한다.
정확하게 호출 표현식의 형태, 즉 다른 무엇이 아닌 함수를 호출한 방법이 호출된 컨텍스트의 this 값에 영향을 준다.
this값은 함수가 어떻게 정의되었는가에 따라 정해진다. 전역 함수라면this는 전역 객체를 값으로 갖게 되고, 객체의 메서드라면this는 항상 이 객체를 값으로 갖는다.
function foo() {
console.log(this);
}
foo(); // global
console.log(foo === foo.prototype.constructor); // true
foo.prototype.constructor(); // foo.prototype
위의 코드가 무슨 의미인지 모를 수 있다.
먼저 foo === foo.prototype.constructor 이 부분을 보면 전역 함수인 foo 가 foo.prototype.constructor 가 같으므로 둘 다 전역이라고 생각할 수 있다.
그렇다면 foo.prototype.constructor 를 실행하게 되면, 당연히 this 는 global이 되어야 한다고 생각한다.
그러나 실제 결과는 다르다! 이것과 유사하게 어떤 객체의 메서드로 정의된 함수를 호출하는 경우에서도 this 가 달라질 수 있다.
var foo = {
bar: function () {
console.log(this);
console.log(this === foo);
}
};
foo.bar(); // foo, true
var exampleFunc = foo.bar;
console.log(exampleFunc === foo.bar); // true
exampleFunc(); // global, false
이 경우도 똑같다고 생각하면 된다. exampleFunc === foo.bar 의 결과가 같다면 this 는 같은 것이 나올거라 일반적으로 생각을 할 것이다.
그런데 결과를 보게 되면 놀랍다. global이 나온다.
그렇다면 호출 표현식의 형태가 어떻게 this 에 영향을 미칠까?
this 가 갖는 값을 결정하는 과정을 완벽하게 이해하기 위해서, 내부 타입 중에 하나인 레퍼런스 타입(Reference type) 에 대해서 자세하게 알 필요가 있다.
레퍼런스 타입
레퍼런스 타입은 수도 코드를 이용해서 base (프로퍼티가 속해 있는 객체)와 이 base 안에 있는 propertyName 이라는 2개의 프로퍼티를 가진 객체로 나타낼 수 있다.
var valueOfReferenceType = {
base: <base object>,
propertyName: <property name>
};
레퍼런스 타입의 값은 오직 아래의 2가지 경우에만 있을 수 있다. 내가 볼 때 아래에 2가지 경우가 this 를 이해하는데 핵심이다.
1. 식별자(identifier)를 다룰 때
2. 프로퍼티 접근자(property accessor)를 다룰 때.
식별자는 알고리즘이 항상 레퍼런스 타입 값(this와 관련해서 중요하다)을 결과로 돌려준다는 것만 명심하자.
식별자는 변수 이름, 함수 이름, 함수 전달인자의 이름 그리고 전역 객체의 비정규화 프로퍼티의 이름을 뜻한다.
var foo = 10; // 변수이름
function bar() {} // 함수이름
중간결과는 아래와 같이 될 것이다.
var fooReference = {
base: global,
propertyName: 'foo'
};
var barReference = {
base: global,
propertyName: 'bar'
};
레퍼런스 타입 값으로부터 객체가 가진 실제 값을 얻기 위해 쓰이는 GetValue 메서드가 있는데 이 메서드를 수도 코드로 아래와 같이 나타낼 수 있다.
function GetValue(value) {
if (Type(value) != Reference) {
return value; // 레퍼런스 타입이 아니면 값을 그대로 돌려준다.
}
var base = GetBase(value);
if (base === null) {
throw new ReferenceError;
}
return base.[[Get]](GetPropertyName(value))
}
위에서 내부 [[Get]] 메서드는 프로토타입 체인으로부터 상속된 프로퍼티까지 분석해서 객체 프로퍼티의 실제 값 을 돌려준다.
GetValue(fooReference); // 10
GetValue(barReference); // function object "bar"
(중요)프로퍼티 접근자는 점 표기법(프로퍼티 이름이 정확한 식별자이고 미리 알 수 있을 때)이나 대괄호 표기법의 2가지 방법으로 표기할 수 있다.
foo.bar();
foo['bar']();
이번에도 중간 계산의 결과로 레퍼런스 타입의 값을 갖게 된다.
var fooBarReference = {
base: foo,
propertyName: 'bar'
};
GetValue(fooBarReference); // function object "bar"
그렇다면, 레퍼런스 타입의 값과 함수 컨텍스트의 this 값은 어떤 관계일까? 이 부분이 가장 중요하며, 이 글의 메인이다.
함수 컨텍스트의 this 값을 결정하는 일반적인 규칙은 다음과 같이 말할 수 있다.
함수 컨텍스트의 this 값은 호출자가 제공하며 호출 표현식의 현재 형태에 의해서 그 값이 결정된다(함수 호출이 문법적으로 어떻게 이뤄졌는지에 따라서).
호출 괄호(…)의 왼편에 레퍼런스 타입의 값이 존재하면, this 는 레퍼런스 타입의 this 값인 base 객체를 값으로 갖는다.
다른 모든 경우에는(레퍼런스 타입이 없는 다른 모든 값의 경우), this 값은 항상 null로 설정된다. 그러나 null 은 this 의 값으로 의미가 없기 때문에 암묵적으로 전역 객체로 변환된다.
예제
function foo() {
return this;
}
foo(); // global
호출 괄호 왼쪽에 레퍼런스 타입 값이 있다. (foo 는 함수이름으로 식별자이다)
var fooReference = {
base: global,
propertyName: 'foo'
};
따라서, this 값은 레퍼런스 타입 값의 base 객체인 전역 객체로 설정된다.
var foo = {
bar: function () {
return this;
}
};
foo.bar(); // foo
여기에서 다시 base 가 foo 객체인 레퍼런스 타입의 값을 갖게 되고, 이것은 bar 함수 활성화 시에 this 값으로 이용된다.
var fooBarReference = {
base: foo,
propertyName: 'bar'
};
그러나, 또 다른 형태의 호출 표현식으로 함수를 활성화하면 this 값은 달라진다.
var test = foo.bar;
test(); // global
test 가 식별자가 되면서 다른 레퍼런스 타입 값을 만들기 때문에, 이 레퍼런스 타입의 base (전역 객체)가 this 값으로 사용된다.
var testReference = {
base: global,
propertyName: 'test'
};
이제는 다른 형태의 호출 표현식으로 활성화된 같은 함수가, 또한 다른 this 값을 갖는지를 정확하게 이야기할 수 있다
=> 레퍼런스 타입의 중간값이 달라서 일어나는 현상
function foo() {
alert(this);
}
foo(); // 전역이기 때문에
var fooReference = {
base: global,
propertyName: 'foo'
};
alert(foo === foo.prototype.constructor); // true
// 호출 표현식의 또 다른 형태
foo.prototype.constructor(); // foo.prototype이기 때문에
var fooPrototypeConstructorReference = {
base: foo.prototype,
propertyName: 'constructor'
};
호출 표현식 형태에 따라 this 값이 동적으로 결정되는 또 다른 예제가 있다.
function foo() {
alert(this.bar);
}
var x = {bar: 10};
var y = {bar: 20};
x.test = foo;
y.test = foo;
x.test(); // 10
y.test(); // 20
함수 호출과 비-레퍼런스 타입(Function call and non-Reference type)
호출 괄호의 왼편에 레퍼런스 타입이 아닌 다른 값이 오는 경우 this 값은 자동으로 null 값을 가지게 된다. 그리고 이것을 엔진은 자동으로 전역 객체로 출력한다.
(function () {
alert(this); // null => global
})();
딱 위의 경우가 좋은 예시이다. 이것은 레퍼런스타입(식별자, 프로퍼티 접근자)가 아니다. 따라서 레퍼런스타입이 존재하지 않는다. 즉 null 이다 그러므로 전역객체를 출력한다.
var foo = {
bar: function () {
alert(this);
}
};
foo.bar(); // Reference, OK => foo
(foo.bar)(); // Reference, OK => foo
(foo.bar = foo.bar)(); // global?
(false || foo.bar)(); // global?
(foo.bar, foo.bar)(); // global?
이 경우가 정말 어렵다. 왜 아래의 3개의 경우에는 왜 전역객체가 나오는 것일까?
즉 아래의 3개는 레퍼런스 타입 값이 null이라는 것이다.
두번째 경우에는 그룹핑 연산자가 레퍼런스 타입의 값으로부터 객체의 실제 값을 얻기 위한 메서드인 GetValue 에 적용되지 않는다. 그래서 그룹핑 연산자가 평가 결과를 반환할 때도 여전히 레퍼런스 타입의 값이 존재 하게 되는데, 이것이 this 값이 다시 base 객체로 설정되는 이유다.
세번째의 경우는, 그룹핑 연산자와 다르게 할당 연산자는 GetValue 메서드를 호출한다. 반환의 결과로 this 가 null로 설정되었음을 의미하는 함수 객체(레퍼런스 타입 값은 아닌)가 반환되기 때문에, 이는 결국 전역 객체가 된다.
네번째와 다섯번째의 경우도 유사하다. 콤마 연산자와 논리적 OR 표현식은 GetValue 메서드를 호출하고, 따라서 레퍼런스 타입의 값을 잃어버리고 함수 타입의 값을 갖게 되어 this 의 값은 전역 객체로 설정된다.
레퍼런스 타입과 값이 null 인 this(Reference type and null this value) 위에도 말은 했지만 레퍼런스타입의 값이 null이 되면 this는 전역객체가 된다고 했다. 이것은 레퍼런스 타입 값의 base 객체가 활성화 객체인 경우와 관련이 있다.
function foo() {
function bar() {
alert(this); // global
}
bar(); // AO.bar()와 같다.
}
활성화 객체는 항상 this 값으로 null을 반환한다.
예외의 with함수
with 객체가 함수 이름 프로퍼티를 갖는 경우, with 문의 블록 안에서 함수를 호출할 때는 예외일 수 있다. with 문은 자신의 스코프 체인의 가장 앞, 즉 활성화 객체 앞에 그 객체를 추가한다.
따라서 레퍼런스 타입 값을 얻으려 할 때(식별자나 프로퍼티 접근자를 이용해서) 활성화 객체가 아닌 with 문의 객체를 base 객체로 갖게 된다.
그런데, 이는 with 객체가 스코프 체인에서 더 상위에 있는(전역 객체 또는 활성화 객체) 객체까지 가려버리기 때문에 중첩함수뿐만 아니라 전역 함수와도 관련이 있다.
var x = 10;
with ({
foo: function () {
alert(this.x);
},
x: 20
}) {
foo(); // 20
}
// because
var fooReference = {
base: __withObject,
propertyName: 'foo'
};
catch 절의 실제 파라미터인 함수를 호출할 것도 이와 유사하다.
이 경우에 항상 스코프 체인의 가장 앞, 즉 활성화 객체나 전역 객체 앞에 catch 객체가 추가된다.
그러나 이 동작은 ECMA-262-3 의 버그로 인정되어 새로운 버전인 ECMA-262-5에서는 수정된다. ECMA-262-5는 이러한 경우 this 값이 catch 객체가 아닌 전역 객체로 설정된다.
try {
throw function () {
alert(this);
};
} catch (e) {
e(); // __catchObject - ES3, global - ES5에서는 수정
}
// on idea
var eReference = {
base: __catchObject,
propertyName: 'e'
};
// 그러나, 이것은 버그이기 때문에
// this는 강제로 전역 객체를 참조하게 된다.
// null => global
var eReference = {
base : global,
propertyName: 'e'
}
생성자로 호출된 함수 안의 this(This value in function called as the constructor)
function A() {
alert(this); // 새롭게 만들어진 객체, 아래에서 a 객체
this.x = 10;
}
var a = new A();
alert(a.x); // 10
이 경우는, new 연산자가 A함수의 내부 [[Construct]] 메서드를 호출하고 차례로, 객체가 만들어진 후에 A와 모두 같은 함수인 내부의 [[Call]] 메서드를 호출하여 this 값으로 새롭게 만들어진 객체를 갖게 된다.
함수 호출 시 this 를 수동으로 지정하기(Manual setting of this value for a function call)
함수 호출 시에 this 값을 수동적으로 지정할 수 있게 해주는 두 가지 방법이 Function.prototype 에 정의되어 있다(prototype 에 정의되어 있으므로 모든 함수가 이용 가능). 바로 apply 와 call 메서드다.
var b = 10;
function a(c) {
alert(this.b);
alert(c);
}
a(20); // this === global, this.b == 10, c == 20
a.call({b: 20}, 30); // this === {b: 20}, this.b == 20, c == 30
a.apply({b: 30}, [40]) // this === {b: 30}, this.b == 30, c == 40
Reference
ECMA-262-3 ScopeChain
소개
- 실행 컨텍스트의 데이터(변수, 함수 선언 그리고 함수의 매개변수)는 변수 객체의 프로퍼티( VO )로 저장된다.
Context = VO|AO + this + SC
- 컨텍스트로 진입 할 때 매번 초깃값을 갖는 변수 객체를 생성하며(선언 + 초기화 == 호이스팅(Hoisting)), 코드 실행할 때 값을 갱신(할당)한다.
이번에는 ScopeChain에 대해서 알아보자.
정의
ScopeChain은 중첩 함수와 관련이 있다.
중첩함수란 함수 안에 함수가 있는 것을 말한다.
심지어 부모 함수가 이러한 중첩 함수를 결과값으로 반환 가능하다.
var x = 10;
function foo() {
var y = 20;
function bar() {
alert(x + y);
}
return bar;
}
foo()(); // 30
This 편에서 나왔지만 모든 컨텍스트는 자신의 고유 변수 객체를 가진다.
전역 컨텍스트는 자기 자신을 변수 객체(VO_global)로 가지며, 함수 컨텍스트는 활성화 객체(AO)를 가진다.
- 전역 컨텍스트 =
VO + SC + this - 함수 컨텍스트 =
AO + SC + this
ScopeChain은 내부 컨텍스트가 이용하는 모든(부모) 변수 객체의 리스트다. 변수를 검색할 때 이 체인을 이용한다.
위의 경우에서는 bar 컨텍스트의 ScopeChain은 AO(bar), AO(foo), VO(global)를 갖는다.
순서 또한 위와 같다. 즉 처음에 위치한 것은 자기 자신이라는 것이다.
SC는 내부 컨텍스트가 이용하는 모든 변수 객체의 리스트
ScopeChain은 실행 컨텍스트와 관련 있으며, 식별자 해석 시 변수 검색에 이용하는 변수 객체의 체인이다.
- ScopeChain은 함수를 호출할 때 생성된다.(실행 X)
- 활성화 객체와 함수의 내부
[[scope]]프로퍼티를 가진다.
내부의 모습
activeExecutionContext = {
VO: {...}, // or AO
this: thisValue,
Scope: [ // ScopeChain(scope chain)
// 식별자 검색에 이용할 모든 변수 객체의 리스트
]
};
Scope의 정의
Scope = AO + [[scope]]
예를 들기 위해서 스코프와 [[Scope]] 를 ECMAScript 의 일반 배열로 나타낼 수 있다.
var Scope = [VO1, VO2, ..., VOn]; // ScopeChain
var VO1 = {__parent__: null, ... other data};
var VO2 = {__parent__: VO1, ... other data};
...
함수 라이프 사이클(Function life cycle)
함수의 라이프 사이클은 생성 단계, 활성화 단계(call) 의 2가지로 나뉜다.
함수 생성
컨텍스트 단계로 들어갈 때 변수/활성화 객체(VO/AO)가 함수 선언으로 들어간다.
var x = 10;
function foo() {
var y = 20;
alert(x + y);
}
foo(); // 30
함수가 활성화가 되면 함수는 30을 출력한다.
여기에서 변수 y는 함수 foo에서 정의되어있지만, 변수 x는 foo의 컨텍스트에 정의되어 있지 않다. 그러므로 foo의 AO에 추가되지 않는다. 그렇다면 x 는 foo 에 존재하지 않는 것인가?
fooContext.AO = {
y: undefined // undefined – 컨텍스트 접근시, 20 – 활성화시
};
foo 컨텍스트의 활성화 객체는 y 프로퍼티만을 가진다.
그렇다면 어떻게 해서 함수 foo 가 변수 x 에 접근할 수 있을까?
[[Scope]]는 현재 함수 컨텍스트의 상위에 있는 모든 부모 변수 객체의 계층 체인 이다. 이 체인은 함수가 생성될 때 함수에 저장된다.
함수를 생성할 때 [[Scope]] 프로퍼티가 함수에 저장되는데, 일단 한 번 저장되면 함수가 사라질 때까지 정적으로 변하지 않는다 는 사실을 주목하자. 함수를 결코 호출할 수 없어도, 함수 객체는 이미 [[Scope]] 프로퍼티를 가지고 있다.
foo.[[Scope]] = [
globalContext.VO // === Global
];
함수 활성화
컨텍스트로 진입하고 AO/VO가 만들어진 후에, 컨텍스트의 scope 프로퍼티는 다음과 같이 정의된다.
Scope = AO|VO + [[Scope]]
여기서 중요한 것은 활성화 객체가 Scope 배열의 첫 번째 원소로 제일 앞으로 온다는 것이다.
Scope = [AO].concat([[Scope]]);
식별자 해석은 변수(또는 함수 선언)가 ScopeChain의 어떤 변수 객체에 속하는지를 결정하는 과정이다.
식별자 해석 과정은 변수의 이름에 해당하는 프로퍼티를 검색하는 과정을 포함하며, ScopeChain 가장 깊은 곳에 있는 컨텍스트의 변수 객체부터 시작해서 가장 위에 있는 변수 객체까지 연속적으로 검사하는 과정이다.
그 결과 현재 컨텍스트의 지역 변수는 부모 컨텍스트에 있는 변수보다 검색 우선순위를 가지며, 이름이 같지만 서로 다른 컨텍스트에 존재하는 두 변수가 있으면, 더 깊은 컨텍스트에 있는 변수가 우선한다. 즉 가까운 곳에 있는 변수가 우선순위가 높다는 것이다.
var x = 10;
function foo() {
var y = 20;
function bar() {
var z = 30;
alert(x + y + z);
}
bar();
}
foo(); // 60
전역 컨텍스트의 변수 객체 :
globalContext.VO === Global = {
x: 10
foo: <reference to function>
};
foo 생성 시점에 foo의 [[Scope]] 프로퍼티 :
foo.[[Scope]] = [
globalContext.VO
];
foo 함수의 활성화 시점(컨텍스트로 진입하는 단계)에 foo 컨텍스트의 활성화 객체 :
fooContext.AO = {
y: 20,
bar: <reference to function>
};
foo 컨텍스트의 ScopeChain :
fooContext.Scope = fooContext.AO + foo.[[Scope]]
fooContext.Scope = [
fooContext.AO,
globalContext.VO
];
중첩된 bar 함수가 생성되는 시점에 bar 함수의 [[Scope]] :
bar.[[Scope]] = [
fooContext.AO,
globalContext.VO
];
bar 활성화 시점에 bar 컨텍스트의 활성화 객체 :
barContext.AO = {
z: 30
};
bar 컨텍스트의 ScopeChain :
barContext.Scope = barContext.AO + bar.[[Scope]] // i.e.:
barContext.Scope = [
barContext.AO,
fooContext.AO,
globalContext.VO
];
스코프의 특징(Scope features)
클로저
ECMAScript의 클로저는 [[Scope]] 프로퍼티와 직접적으로 관련이 있다. [[Scope]] 는 함수를 생성할 때 함수에 저장되어서, 함수 객체가 사라질 때까지 존재한다. 실제로, 클로저는 정확하게 함수 코드와 [[Scope]] 프로퍼티의 조합이다
var x = 10;
function foo() {
alert(x);
}
(function () {
var x = 20;
foo(); // 10, but not 20
})();
변수 x는 foo 함수의 [[Scope]] 에 있는 것을 알 수 있다. 변수를 검색할 때, 함수 호출 시점의 동적인 체인(이 경우 변수 x의 값은 20이 될 것이다)이 아닌, 함수 생성 순간에 정의된 어휘적인 체인을 이용하였다.
function foo() {
var x = 10;
var y = 20;
return function () {
alert([x, y]);
};
}
var x = 30;
var bar = foo(); // 익명 함수를 반환한다.
bar(); // [10, 20]
위이 예제에서도 역시 식별자 해석에 함수 생성 시점에 정의된 어휘적 ScopeChain을 이용했다. 변수 x를 30이 아닌 10으로 해석했다. 게다가, 이 예제는 함수의 [[Scope]] (함수 foo가 반환한 익명 함수의 경우에)가 심지어 생성된 함수의 컨텍스트가 이미 종료되고 난 이후에도 존재하고 있음을 명확하게 보여준다.
Function 생성자로 생성한 함수의 [[Scope]]
위의 예제에서 함수 생성시에 [[Scope]] 프로퍼티를 가져오고 이 프로퍼티를 통해서 모든 부모 컨텍스트의 변수에 접근한다는 것을 보았다. 그러나, 이 규칙에는 한 가지 중요한 예외가 있는데, Function 생성자를 이용해서 함수를 생성하는 경우는 다르다.
var x = 10;
function foo() {
var y = 20;
function barFD() { // FunctionDeclaration
alert(x);
alert(y);
}
var barFE = function () { // FunctionExpression
alert(x);
alert(y);
};
var barFn = Function('alert(x); alert(y);');
barFD(); // 10, 20
barFE(); // 10, 20
barFn(); // 10, "y" is not defined
}
foo();
위에 보이듯이 생성자로 만든 함수는 Scope가 다르다. 그러나 x에는 접근을 한다. 이것은 [[Scope]]로 global은 가진다는 것이다.
2차원 ScopeChain 검색
ScopeChain 검색의 중요한 포인트는 ECMAScript 의 프로토타입적인 성격 때문에 변수 객체의 프토토타입 또한 고려해야 한다는 점이다. 객체 내에서 직접적으로 프로퍼티를 찾지 못한다면, 프로토타입 체인까지 검색한다. 즉, 일종의 2차원 체인 검색이다. (1) ScopeChain 연결, (2) 그리고 깊은 프로토타입 체인 연결에 있는 모든 ScopeChain 연결을 검색 한다.
function foo() {
alert(x);
}
Object.prototype.x = 10;
foo(); // 10
쉽게 말하면 역시 scope를 검색했는데, 없다면 protptype chain까지 검색한다는 것이다.
전역 컨텍스트와 eval 컨텍스트의 ScopeChain
전역 컨텍스트의 ScopeChain은 오직 전역 객체만을 갖는다. 그리고 eval 코드의 컨텍스트는 호출 컨텍스트와 같은 ScopeChain을 갖는다.
무조건 글로벌이라고 생각하면 된다.
globalContext.Scope = [
Global
];
evalContext.Scope === callingContext.Scope;
코드 실행 중 ScopeChain에 영향을 미치기
ECMAScript에는 코드 실행 런타임에 ScopeChain을 변경할 수 있는 두 가지 구문이 있다.
with문과 catch절이다.
구문 내에 나타나는 식별자를 찾기 위한 객체를 ScopeChain의 가장 앞에 추가한다. 이 중에 하나를 코드에 적용하면, ScopeChain은 아래와 같이 변경된다.
Scope = withObject|catchObject + AO|VO + [[Scope]]
with문의 경우에는 파라미터로 넘겨 받은 객체를 추가한다(결과, 이 객체의 프로퍼티에 접두사를 붙이지 않고 접근할 수 있다)
var foo = {x: 10, y: 20};
with (foo) {
alert(x); // 10
alert(y); // 20
}
Scope = foo + AO|VO + [[Scope]]
var x = 10, y = 10;
with ({x: 20}) {
var x = 30, y = 30;
alert(x); // 30
alert(y); // 30
}
alert(x); // 10
alert(y); // 30
x = 10, y = 10- 객체 {
x : 20}을 ScopeChain의 앞에 추가한다. - 컨텍스트 진입 단계에서 모든 변수를 해석하고 추가했기 때문에
with내에서var구문을 만났을 때 아무것도 만들지 않는다. - 오직
x의 값을 수정하는데, 정확하게는 두 번째 단계에서 ScopeChain의 앞에 추가된 객체 내에서 해석되는x를 말한다. 20이었던x의 값이 10이 된다. - 또한 위의 변수 객체 내에서 해석되는
y도 변경한다. 결과적으로 10이었던y의 값이 30이 된다. - 다음으로
with문이 종료된 후에, 스페셜 객체는 ScopeChain에서 제거된다(x의 값이 변경되고, 30 또한 객체에서 제거된다). 즉, ScopeChain 구조가with문에 의해서 확장되기 이전 상태로 돌아온다. - 마지막에 있는 두 번의
alert호출을 통해서 알 수 있듯이, 현재 변수 객체 내에 있는x의 값은 같은 상태로 남아있고,y의 값은with문 내에서 변경한 상태 그대로 30이다.
catch 절 또한 exception 파라미터에 접근하기 위해서 exception 파라미터의 이름을 유일한 프로퍼티로 갖는 중간 스코프 객체를 만들며, 이 객체를 ScopeChain의 앞에 추가한다.
try {
...
} catch (ex) {
alert(ex);
}
var catchObject = {
ex: <exception object>
}
Scope = catchObject + AO|VO + [[Scope]]
catch절 내의 작업이 종료된 후에, ScopeChain은 이전 상태로 돌아온다.
Reference
ECMA-262-3 Function
도입
함수가 컨텍스트의 변수 객체(VO)에 어떤 영향을 미치며, 각 함수의 스코프 체인에는 무엇이 들어가는지 알아보자.
var foo = function () {...};
function foo() {...}
(function () {...})();
위와 같이 함수의 경우는 3가지가 있다.
선언식, 표현식, 즉시 실행
3가지의 차이점과 특징은 무엇인가에 대해서 자세히 알아보자.
함수의 종류
ECMAScript에는 세 가지 종류의 함수가 있고, 각각의 고유한 특징을 갖는다.
함수 선언식
함수 선언식(FD)은 아래와 같은 특징을 가진다.
- 반드시 이름을 가진다.
- 소스 코드 위치에 자리한다. 프로그램 레벨이나 다른 함수의 몸체 안에 직접 위치한다.
- 컨텍스트 진입 시점에 생성한다.
- 변수 객체에 영향을 준다.
function exampleFunc() {...}
가장 중요한 특징은 변수 객체(VO)에 영향을 미친다는 것이다. 이 함수는 컨텍스트의 변수 객체에 들어간다.
코드 실행 단계에서 이미 사용 가능하다(FD가 컨텍스트 단계 시작 시 VO에 저장되므로 실행이 시작되기 전).
foo(); // 작동함
function foo() {
alert('foo');
}
위의 소스는 그렇다면 Global의 VO에 들어있을 것이다. (흔히 호이스팅이라 불린다.)
소스 코드 내에 함수를 정의하는 위치는 중요하다.
// 함수를 다음 2가지 방법으로 선언할 수 있다.
// 1) 전역 컨텍스트에 직접.
function globalFD() {
// 2) 또는 다른 함수의 몸체 내에서 선언.
function innerFD() {}
}
함수를 선언할 수 있는 위치는 결국 두 군데가 있는 것이다.
함수를 선언하는 다른 방법이 있다.
함수 표현식
함수 표현식(FE)은 아래와 같은 특징을 가진다.
- 표현식 위치에만 정의할 수 있다.
- 선택적으로 이름을 가질 수 있다. (없을 수 있다.)
- 함수 표현은 변수 객체에 영향을 주지 않는다.
- 코드 실행 시점에 생성 한다.
이 함수 타입의 주요 특징은 항상 표현식 위치에 있다는 것이다.
var foo = function () {...};
위의 경우는 익명 함수 표현식을 foo 변수에 할당하는 것이다.
할당이 끝나면 foo를 호출할 수 있다.
선택적으로 이름을 줄 수 있다.
var foo = function _foo() {...};
여기에서 주목해야 할 것은 함수 내부에서 _foo라는 이름을 사용할 수 있다. (외부는 사용불가)
FE를 식별자에 할당하면 FD와 구분하기 어려워진다. 하지만 FE가 항상 표현식에 위치 한다는 사실을 알고 있다면, 둘을 쉽게 구분할 수 있다.
다음 예제에는 다양한 ECMAScript 표현식이 나와있는데, 모든 함수는 함수 표현식이다.
// 괄호(그룹화 연산자) 안에서는 표현식이 된다.
(function foo() {});
// 배열 리터럴 안에 있을 경우에도 표현식이다.
[function bar() {}];
// 콤마 또한 표현식으로 처리한다.
1, function baz() {};
위의 경우의 표현식들은, 표현식 위치에서 함수를 사용하고 변수 객체를 오염시키지 않으려면 필요하다.
function foo(callback) {
callback();
}
foo(function bar() {alert('foo.bar');});
foo(function baz() {alert('foo.baz');});
FE를 변수에 할당하면, 함수는 메모리에 계속 존재한다. 따라서 변수명으로 접근할 수 있다(변수가 변수 객체(VO)에 영향을 주기 때문이다). Global VO에 존재하기 때문에 접근이 가능하다.
var foo = function () {
alert('foo');
};
foo();
보조적인 역할을 하는 도우미 데이터를 외부 컨텍스트에 감추기 위해서 유효범위를 캡슐화하는 예제가 있다(FE를 생성 직후 호출).
var foo = {};
(function initialize() {
var x = 10;
foo.bar = function () {
alert(x);
};
})();
foo.bar(); // 10;
alert(x); // "x" is not defined
함수 foo.bar ( foo 의 [[Scope]] 프로퍼티에 있는)는 initialize 함수의 내부에 있는 변수 x에 접근할 수 있다. 그러나 외부에서 x를 직접 접근할 수 없다.
많은 라이브러리가 private 데이터를 만들어서 보조 개체를 감추는 데 이용한다.
초기화하는 FE 이름은 종종 생략하기도 한다.
(function () {
// 초기화 스코프
})();
런타임에 조건에 따라 FE를 생성함으로써 VO를 오염시키지 않는 예제도 있다.
var foo = 10;
var bar = (
foo % 2 == 0 ?
function () { alert(0); }
:
function () { alert(1); }
);
bar(); // 0
감싸는 괄호에 대한 질문
왜 괄호로 함수를 감싸야 선언과 동시에 호출할 수 있지?
그 답은 바로 표현식 구문이 가지는 제약 때문이었다.
표준에 따라서, 표현식 구문은 여는 중괄호, { 로 시작할 수 없다. 블록과 구분할 수 없기 때문이다. 그리고 함수 선언과 구분하기 힘들기 때문에 함수 키워드로 시작해서도 안 된다.
다시 말해서, 즉시 실행 함수(function 키워드로 시작하는)를 만들기 위해서 아래와 같이 함수 선언식을 작성했다면
function () {...}();// 또는 아래와 같이 이름이 있는.
function foo() {...}();
두 경우 모두 파서가 해석 에러를 보고할 것이다.
이 에러의 원인은 다양하겠지만, 전역 코드에 이렇게 선언을 하면(즉, 프로그램 레벨에), function 키워드로 시작하기 때문에 파서는 코드를 함수 선언식으로 이해한다.
첫 번째 경우는 함수의 이름이 없어서 SyntaxError를 보고한다.
두 번째의 경우는 함수에 이름(foo)이 존재하기 때문에 파서가 정상적인 함수 선언으로 처리한다. 하지만 내부에 표현식이 없는 그룹화 연산자 를 사용하고 있음을 알리는 문법 에러가 발생한다. 이 경우에 함수 선언 뒤에 오는 것은 함수 호출을 위한 괄호가 아니라 그룹화 연산자일 뿐이다. 만약 코드를 다음과 같이 작성했다면,
// "foo"는 함수 선언이다
// 그리고 실행 컨텍스트 진입 시점에 생성한다.
alert(foo);
// function
function foo(x) {
alert(x);
}(1); // 이것은 호출이 아니라, 그룹화 연산자다.
foo(10);
// 10
함수 선언과 표현식 (1)을 가지고 있는 그룹화 연산자가 있어서 두 구문 모두 아무런 문제가 없다.
위의 예제는 아래의 예제와 같다.
// 함수 선언
function foo(x) {
alert(x);
}
// 표현식이 있는 그룹화 연산자
(1);
// 다른 (function) 표현식을 갖는 또 다른 그룹화 연산자
(function () {});
// 내부에 있는 표현식
("foo");
ECMA 스펙상으로 볼 때, 위의 코드는 잘못된 구문이다(표현식 구문은 function 키워드로 시작할 수 없다). 하지만 아래에 나와 있는 것처럼, 문법 에러를 제공하는 ECMAScript 구현체는 하나도 없으며 모두 이를 각자 나름의 방식으로 처리한다.
지금까지 설명한 내용을 가지고, 어떻게 파서에게 함수를 생성과 동시에 실행하고 싶다고 할 수 있을까?
함수 선언식이 아닌 함수 표현식을 사용하면 된다.
표현식을 만드는 가장 간단한 방법은 위에서 이야기했듯이 그룹화 연산자를 사용한다. 그룹화 연산자 안에 표현식을 두면, 파서는 함수 표현식(FE)인 코드를 구분할 수 있으며 이에 따라 모호함도 사라진다. 이러한 함수는 코드 실행 단계 동안에 만들어지고, 함수 실행이 끝난 후에는 사라진다(함수를 참조하고 있는 곳이 없다면).
(function foo(x) {
alert(x);
})(1); // 이건 그룹화 연산자가 아닌 함수 호출이다.
예제의 마지막에 있는 괄호는 FD의 경우처럼 그룹화 연산자가 아니라 함수 호출 괄호다.
다음 예제에 나오는 즉시 호출 함수는 괄호로 감쌀 필요가 없다는 것에 주목하자. 이유는 함수가 표현식의 위치에 있어서 파서가 이를 코드 실행 시점에 생성하는 FE로 처리해야 한다는 것을 이미 알고 있기 때문이다.
var foo = {
bar: function (x) {
return x % 2 != 0 ? 'yes' : 'no';
}(1)
};
alert(foo.bar); // 'yes'
얼핏보면 foo.bar는 함수가 아니라 문자열처럼 보인다. 여기에 있는 함수는 프로퍼티를 초기화할 때만 사용하는데, 조건 매개변수 값에 따라서 값을 돌려주는 함수를 만들고 바로 실행한다. 따라서, 괄호를 묻는 질문에 완벽한 대답은 다음과 같다.
:star: 중요 :star:
**그룹화 괄호는 함수가 표현식의 위치에 있지 않을 때 필요하고, 함수를 생성 후 즉시 실행하고 싶은 경우에는 직접 함수를 FE로 변환한다.
파서가
FE로 처리해야 한다는 것을 아는 경우, 즉 함수가 이미 표현식의 위치에 있는 경우에는 괄호가 필요 없다.**
괄호를 감싸는 방법 외에 함수를 FE 타입으로 변경할 수 있는 다른 방법이 있다. 예를 들어,
1, function () {
alert('익명함수를 호출합니다.');
}();// 또는 이렇게,
!function () {
alert('ECMAScript');
}();// 그리고 수동적으로 변경하는 다른 방법들...
올바른 표현식
(function () {})();
(function () {}());
구현의 확장 : Function문
다음에 나오는 예제 코드는 어떤 ECMAScript 구현체도 명세를 따르지 않았음을 보여준다.
if (true) {
function foo() {
alert(0);
}
} else {
function foo() {
alert(1);
}
}
foo(); // 1 또는 0? 다른 ECMAScript 엔진에서 테스트 해보자.
표준에 비춰볼 때 이 구조는 문제가 있다. 코드 블럭 안에 함수 선언식(FD)을 둘 수 없기 때문이다(지금은 if와 else가 FD를 가지고 있음). 위에서 이야기 했듯이, FD는 프로그램 레벨이나 다른 함수의 몸체 안에 직접 위치해야 한다.
코드 블럭은 오직 구문만 가질 수 있기 때문에 위의 예제는 잘못되었다. 블럭 내에 함수는 표현식의 위치에만 나올 수 있으며, 함수를 정의할 때는 여는 중괄호(코드 블럭과 구분할 수 없음)나 함수 키워드로 시작할 수 없다(FD와 구분할 수 없음).
하지만 표준 문서의 error processing 섹션은 ECMAScript 구현체가 프로그램 구문을 확장할 수 있도록 허용하고 있다. 그리고 블럭 안에 등장하는 함수 처리가 이러한 확장 중에 하나다. 오늘날 존재하는 모든 구현체는 이 경우에 예외를 던지지 않고 각자 고유의 방식으로 처리한다.
위 예제의 if-else 분기문은 두 함수 중 어떤 것을 정의할지 선택할 수 있다고 가정한다. 이 결정은 런타임에 이루어지기 때문에, 함수 표현식(FE)을 사용해야 한다. 하지만 대부분의 구현체는 단순하게 컨텍스트 진입 시점에 두 개의 함수 선언식(FD)을 모두 생성한다. 두 함수 모두 같은 이름을 사용하기 때문에, 마지막에 선언한 함수만 호출할 수 있다. 이런 이유로 이 예제를 실행하면 else 로 코드 제어가 이동할 수 없음에도 불구하고 foo 함수는 1을 출력한다.
기명함수 표현식의 특징(Named Function Expression, NFE)
이름을 갖는 FE(기명 함수 표현식, 줄여서 NFE)는 중요한 특징 하나를 가지고 있다.
함수 표현식을 정의할 때 이야기 했던 것처럼
- 함수 표현식은 컨텍스트의 변수 객체에 영향을 주지 않는다
- 하지만 FE는 이름으로 자기 자신을 재귀 호출할 수 있다.
(function foo(bar) {
if (bar) {
return;
}
foo(true); // "foo" 이름을 이용할 수 있다.
})();
// 하지만 외부에서는 "foo"를 이용할 수 없다.
foo(); // "foo" is not defined
foo를 어디에 보관하는 걸까? foo의 활성화 객체 안도 아니다. foo 함수 내부에서 foo라는 이름을 정의한 적이 없다. 그렇다면 foo를 생성하는 컨텍스트의 변수객체 안도 역시 아니다. FE는 VO에 영향을 주지 않는다는 사실을 외부에서 foo를 호출하면서 확인했다. 그렇다면 어디일까?
코드 실행 시점에 인터프리터가 기명 함수 표현식(NFE)을 만나면. 함수 표현식을 만들기 전에 보조 특수 객체(auxiliary specilal object) 를 만들고 스코프 체인의 가장 앞에 이 특수 객체를 추가 한다. 그런 다음 함수 표현식을 만드는데, 이 때 함수에 [[Scope]] 프로퍼티(Scope chain에서 배웠듯이)가 생긴다. 여기에는 함수를 생성하는 컨텍스트의 스코프 체인이 들어있다(즉, [[Scope]] 안에 특수 객체가 위치한다). 다음으로, 기명 함수 표현식을 특수 객체에 고유 프로퍼티로 추가한다. 이 프로퍼티의 값은 함수 표현식을 참조한다. 그리고 마지막으로 부모의 스코프 체인에서 특수 객체를 제거한다.
specialObject = {};
Scope = specialObject + Scope;
foo = new FunctionExpression;
foo.[[Scope]] = Scope;
specialObject.foo = foo; // {DontDelete}, {ReadOnly}
delete Scope[0]; // 스코프 체인의 가장 앞에 있는 specialObject를 삭제한다.
따라서, 외부에서는 이 함수의 이름을 사용할 수 없다. 함수의 [[Scope]] 안에 특수 객체가 저장되어 있기 때문에, 내부에서는 이 함수의 이름을 사용할 수 있다.
Reference
[ES3]ECMA-262-3 Closure
프로그래밍 패터다임 중에 하나로 함수형 프로그래밍이 있다.
함수형 언어에서 함수는 데이터다. 초기 js가 만들어질 때 함수형의 영향을 어느정도 받았다. 그래서 함수형과 비슷한점이 존재한다.
함수를 변수에 할당할 수 있고, 다른 함수에 인자로 전달할 수 있으며, 함수의 결과로 반환할 수 있다.
정의
함수 전달인자(Funarg)는 값이 함수인 전달인자다.
function exampleFunc(funArg) {
funArg();
}
// 인자로 함수를 넘기고 있음
exampleFunc(function () {
alert('funArg');
});
전달인자로 다른 함수를 받는 함수를 고차함수(HOF, High Order Function)라고 한다.
리액트를 사용하면 HOF로 구현을 하는 방법론이 나온다. 그 이야기의 시작은 여기서부터라고 생각한다.
고차함수(HOF, High Order Function)는 기능적, 수학적으로 연산자로 볼 수 있다.
위 예제의 exampleFunc 함수가 고차 함수 이다.
함수를 전달인자로 넘길 수 있을 뿐만 아니라, 다른 함수의 결괏값으로 함수를 반환할 수도 있다.
(function functionValued() {
return function () {
alert('returned function is called');
};
})()();// 함수로 반환한 것을 실행시키고 있다.
함수를 일반적인 데이터로 취급을 하고 있다.
함수를 전달하고 함수를 전달자로 받을 수 있으며, 함수를 값으로 반환할 수 있는 함수를 일급객체라 한다.
일급객체(First Class)
ECMAScript에서 모든 함수는 일급 객체다. 자기 자신을 전달인자로 받는 함수를 자기 응용 함수라고 부른다.
(function selfApplicative(funArg) {
if (funArg && funArg === selfApplicative) {
alert('self-applicative');
return;
}
// 자기 자신을 반환한다.
// 전에도 말했지만 자신안에서 자신을 부를 수 있다.
selfApplicative(selfApplicative);
})();
자기 자신을 반환하는 함수를 자기 복제 함수라고 한다. 다른 곳에서는 자가 증식이라고 말하기도 한다고 한다.
(function selfReplicative() {
return selfReplicative;
})();
자기 복제 함수를 호출할 때는 인자로 컬렉션 전체가 아닌 각각의 원소를 하나씩 전달한다.
// 컬렉션 자체를 매개변수로 받아서 처리하는 함수
function registerModes(modes) {
// 인자로 전달받은 배열 modes를 순회하면서 각각의 모드를 등록한다.
modes.forEach(registerMode, modes);
}
// 사용법
registerModes(['roster', 'accounts', 'groups']);
// 자기 복제 함수
function modes(mode) {
registerMode(mode); // 하나의 모드를 등록한다.
return modes; // 함수 자신을 반환한다.
}
// 사용법: 인자로 컬렉션 전체가 아닌 각각의 원소를 하나씩 전달한다.
modes
('roster')
('accounts')
('groups')
이렇게 함수를 호출할 수 있지만, 컬렉션 전체를 전달하는 방식이 더 효율적이고 직관적일 수 있다.
물론 함수 실행 시점에 전달인자로 넘기는 함수의 지역 변수에 접근할 수 있다. 컨텍스트에 진입할 때마다 컨텍스트 내부의 데이터 보관용 변수 객체(VO)를 만들기 때문이다.
function testFn(funArg) {
// funarg 실행 시점에,
// 지역 변수 "localVar"를 이용할 수 있다.
funArg(10); // 20
funArg(20); // 30
}
testFn(function (arg) {
var localVar = 10;
alert(arg + localVar);
});
하지만 Chapter 4. Scope Chain. 에서 봤듯이, ECMAScript의 함수는 부모 함수에 속해 부모 컨텍스트의 변수를 사용할 수 있다.
이는 SC가 있기 때문이다. 이 특징으로 인해서 함수 전달인자 문제(funarg problem) 가 발생하게 된다.
함수 전달인자 문제(Funarg problem)
Stack 지향 프로그래밍 언어는 함수를 호출할 때마다 함수의 지역 변수와 전달인자를 Stack에 넣는다. 그리고 함수를 종료할 때 Stack에서 변수를 제거한다.
이 모델을 적용하면 함수를 값(예를 들어, 부모 함수가 반환하는 값으로서의 함수)으로 사용하기 어렵다.
Stack에서 제거되면 사라진다.- 함수가 자유 변수를 사용할 때 이런 문제가 발생한다.
자유 변수는 함수가 사용하는 변수 중, 파라미터와 함수의 지역 변수를 제외한 변수를 말한다.
function testFn() {
var localVar = 10;
function innerFn(innerParam) {
alert(innerParam + localVar);
}
return innerFn;
}
var someFn = testFn();
someFn(20); // 30
위의 예제의 localVar는 innerFn 함수가 사용하는 자유변수다. Stack 지향 모델이라고 가정해보면
testFn 함수를 종료하면서 모든 지역 변수를 스택에서 제거할 것이고, 때문에 외부에서 innerFn 함수를 실행하려고 할 때(즉 someFn을 사용하려고 하면 localvar는 이미 사라졌으므로) 에러가 발생할 것이다.
또한 위의 예처럼 innerFn함수를 반환하는 것이 아예 불가능하다. innerFn 함수가 testFn의 지역에 있기 때문에 testFn 함수가 종료되면서 innerFn 함수도 사라진다는 것이다.
동적 스코프를 이용하는 시스템에서 함수를 전달인자로 넘길 때 함수 객체가 가진 다른 문제가 있다.
var z = 10;
function foo() {
alert(z);
}
foo(); // 10 - 정적 스코프와 동적 스코프를 둘다 사용
(function () {
var z = 20;
foo(); // 10 – 정적 스코프, 20 – 동적 스코프
})();
// 전달인자로 foo를 넘기는 것과 같다.
(function (funArg) {
var z = 30;
funArg(); // 10 – 정적 스코프, 30 – 동적 스코프
})(foo);
동적 스코프인 경우에는 동적(활동적) 스택을 이용해 변수를 처리한다. 결국 함수를 생성할 때 함수에 저장한 정적(어휘적) 스코프 체인이 아닌, 현재 실행 중인 함수의 동적 스코프 체인에서 자유 변수를 찾는다. 이는 모호한 상황을 만든다.
예를 들어 지역 변수를 스택에서 제거하는 이전 예제와는 달리 z가 계속해서 살아있는 경우, 컨텍스트의 z를 사용해야 할지 아니면 스코프의 z를 사용해야 할지 알 수 없다.
지금까지 함수가 함수를 값으로 반환하거나(upward funarg), 함수를 다른 함수에 전달인자로 전달할 때(downward funarg) 생기는 2가지 유형의 함수 전달인자 문제(funarg problem)를 알아봤다.
클로저는 이러한 문제(및 서브 타입)를 해결하기 위해 나온 개념이다.
클로저(Closure)
클로저는 코드 블럭과 이 코드 블럭을 생성한 컨텍스트가 가진 데이터의 조합이다.
var x = 20;
function foo() {
alert(x); // 자유 변수 "x" == 20
}
// foo의 클로저
fooClosure = {
call: foo // 함수를 참조
lexicalEnvironment: {x: 20} // 자유 변수 검색을 위한 컨텍스트
};
위의 예제의 fooClosure는 물론 의사 코드다. ECMAScript 코드라면 foo 함수는 자신을 생성한 컨텍스트의 스코프 체인을 내부 속성으로 가질 것이다.
종종 어휘적이라는 단어를 생략하기도 하지만, 위 예제의 경우 클로저가 자기 부모의 변수를 소스 코드 내의 어휘적 위치에서 저장한다는 사실에 관심을 집중하자.
다음에 함수를 실행하면 저장한 컨텍스트 내에서 자유 변수를 검색한다. 위의 예제를 통해 ECMAScript에서는 변수 z가 항상 10인 것을 알 수 있다.
위에서 클로저를 정의할 때 코드 블록이라는 일반화한 개념을 사용했지만, 보통 함수라는 용어를 사용한다.
하지만 오로지 함수만 클로저와 관련있는 것은 아니다.
구현에 관해서 이야기해보자면, 컨텍스트가 종료된 후에도 지역 변수를 보존하고 싶다면 스택 기반의 아키텍처는 적합하지 않다. 따라서 이 경우에는 부모 컨텍스트의 데이터를 가비지 콜렉터(GC)와 참조 카운팅을 이용하는 동적 메모리 할당 방식으로 저장해야 한다(힙 기반 구현). 이 방식은 스택 기반보다 느리다. 하지만 함수 안에서 자유 변수를 사용할지 판단하고 이 결정에 따라 스택이나 힙에 데이터를 배치하는 과정을 스크립트 엔진이 해석 시점에 최적화 할 수 있다.
ECMAScript의 클로저 구현(ECMAScript closures implementation)
앞에서 이론적인 이야기를 하면서 마지막에 ECMAScript의 클로저를 언급했다. ECMAScript는 오직 정적(어휘적) 스코프만 사용한다는 사실을 명심하자(Perl 같은 일부 언어는 변수를 정적, 동적 스코프 두 가지 방식으로 선언할 수 있음).
var x = 10;
function foo() {
alert(x);
}
(function (funArg) {
var x = 20;
// funArg는 변수 x를 자신이 선언된 어휘적 컨텍스트에
// 정적으로 저장한다.
// 따라서,
funArg(); // 10, but not 20
})(foo);
기술적으로, 부모 컨텍스트의 변수는 함수 내부의 [[Scope]] 프로퍼티에 저장된다. Chapter 4에서 이야기했던 [[Scope]]와 스코프 체인을 완벽하게 이해했다면 ECMAScript의 클로저를 쉽게 이해할 수 있다.
함수 생성 알고리즘에 나와 있듯이 ECMAScript의 함수는 부모 컨텍스트의 스코프 체인을 가지고 있어서 모든 함수는 클로저다. 함수의 이후 실행 여부와는 상관없이 함수 생성 시점에 부모의 스코프를 함수의 내부 속성에 저장한다.
var x = 10;
function foo() {
alert(x);
}
// foo는 클로저다.
foo: <FunctionObject> = {
[[Call]]: <code block of foo>,
[[Scope]]: [
global: {
x: 10
}
],
... // 다른 프로퍼티들
};
앞에서 언급했듯이, 함수가 자유 변수를 사용하지 않는 경우에는 성능 최적화를 위해 JavaScript 엔진이 부모 스코프 체인을 함수 내부에 저장하지 않을 수도 있다.
그러나 ECMA-262-3 스펙은 이에 대해서 언급하고 있지 않다. 따라서 공식적으로(그리고 기술적 알고리즘에 따라) 모든 함수는 생성 시점에 [[Scope]] 프로퍼티에 스코프 체인을 저장한다.
일부 엔진은 사용자가 클로저 스코프에 직접 접근하는 것을 허용한다.
[[Scope]] 공유(One [[Scope]] value for “them all”)
ECMAScript에서 같은 부모 컨텍스트에서 만들어진 여러 중첩 함수는 같은 클로저 [[Scope]] 객체를 사용한다. 이는 어떤 클로저가 클로저 변수를 수정하면, 변경한 내용을 다른 클로저가 읽을 수 있다는 의미다.
즉, 모든 중첩 함수는 같은 부모의 스코프를 공유한다.
var firstClosure;
var secondClosure;
function foo() {
var x = 1;
firstClosure = function () { return ++x; };
secondClosure = function () { return --x; };
x = 2; // 두 클로저의 [[Scope]] 안에 있는 AO["x"]에 영향을 준다.
alert(firstClosure()); // 3. firstClosure.[[Scope]]
}
foo();
alert(firstClosure()); // 4
alert(secondClosure()); // 3
이와 관련해서 많은 사람이 자주 실수한다. 모든 함수가 고유의 루프 카운터 값을 갖게 만들기 위해 루프 안에서 함수를 생성할 때, 의도하지 않은 결과를 얻는 경우가 종종 있다.
var data = [];
for (var k = 0; k < 3; k++) {
data[k] = function () {
alert(k);
};
}
data[0](); // 3, 0이 아니다.
data[1](); // 3, 1이 아니다.
data[2](); // 3, 2가 아니다.
이전 예제에서 이 동작을 설명했다. 세 함수 모두 같은 컨텍스트의 스코프를 갖는다. 이 세 함수는 모두 [[Scope]] 프로퍼티를 통해 변수를 참조하여 부모 스코프에 존재하는 변수 k를 쉽게 변경할 수 있다.
activeContext.Scope = [
... // 상위의 변수 객체
{data: [...], k: 3} // 활성화 객체
];
data[0].[[Scope]] === Scope;
data[1].[[Scope]] === Scope;
data[2].[[Scope]] === Scope;
따라서 세 함수는 실행 시점에 변수 k에 마지막으로 할당한 값인 3을 사용한다.
클로저의 실제적 사용(Practical usage of closures)
실제로 클로저를 이용하면 다양한 계산을 사용자가 함수 전달인자로 정의할 수 있게 하는 우아한 설계를 할 수 있다. 예를 들어 정렬 조건을 함수 전달인자로 받는 배열 정렬 메소드가 있다.
[1, 2, 3].sort(function (a, b) {
... // 정렬 조건
});
그리고 인자로 전달받은 함수를 배열의 각 원소에 적용한 결과를 갖는 새로운 배열을 만들어 돌려주는 map 메소드같은, 맵핑 고차함수(mapping functionals)가 있다.
[1, 2, 3].map(function (element) {
return element * 2;
}); // [2, 4, 6]
검색 함수를 만들 때 함수를 전달인자로 받아 거의 제한없이 검색 조건을 정의할 수 있게 구현해 놓으면 편리하다.
someCollection.find(function (element) {
return element.someProperty == 'searchCondition';
})
또한, 배열을 순회하면서 각각의 원소에 함수를 적용하는 forEach 메소드와 같은 함수 적용 고차함수(applying functional)도 있다.
[1, 2, 3].forEach(function (element) {
if (element % 2 != 0) {
alert(element);
}
}); // 1, 3
함수 객체의 apply, call 메소드는 함수형 프로그래밍의 고차함수(applying functional)에서 유래했다.
이미 이 메소드에 대해서는 Chapter 3. this 에서 나왔다. 이번에는 함수를 매개변수에 전달하는 방식을 살펴보자(apply 는 전달인자 목록을 받고, call 은 전달인자를 차례로 나열한다).
(function () {
alert([].join.call(arguments, ';')); // 1;2;3
}).apply(this, [1, 2, 3]);
프로그래밍에서 apply는 데이터에 임의의 함수를 적용한다는 의미를 가진다. 만약 함수의 이름과 기능이 확정되어 있고, 그것을 알 수 있다면 함수의 이름과 파라미터 형식에 맞춰서 함수를 호출할 수 있다. 그런데 함수형 언어의 함수는 일급 객체로서 데이터로 취급할 수 있기 때문에 함수를 변수에 저장할 수 있고, 다른 함수의 인자로 전달할 수 있으며, 결괏값으로 반환할 수 있다.
간단히 말해서 함수를 다른 곳으로 넘길 수 있다는 이야기다. 이렇게 함수를 다른 곳으로 넘겼을 때 함수를 받은 쪽에서 받은 함수를 호출할 수 있는 장치가 필요한데, 이 장치를 사용하는 것을 apply라고 한다. JavaScript 역시 함수를 일급 객체로 취급하기 때문에 함수를 apply 하기 위한 call, apply 메소드를 가지고 있다.
그리고 함수들의 집합을 정의역으로 갖는 함수를 수학 용어로는 범함수(functional)라고 한다.
지연 호출은 클로저의 또 다른 중요한 응용 사례다.
var a = 10;
setTimeout(function () {
alert(a); // 10, 1초 후 실행
}, 1000);
var x = 10;
// 예제용
xmlHttpRequestObject.onreadystatechange = function () {
// 데이터가 준비 되었을 때, 지연 호출하는 콜백.
// 콜백을 생성한 컨텍스트가 이미 사라졌는지와는 상관없이
// 여기에서 변수 x에 접근할 수 있다.
alert(x); // 10
};
또는 보조 객체를 감추기 위해 캡슐화한 스코프를 만들 수 있다.
var foo = {};
// 초기화
(function (object) {
var x = 10;
object.getX = function _getX() {
return x;
};
})(foo);
alert(foo.getX()); // 클로저 변수 "x"의 값은 10
Reference
ES3
코어 자바스크립트
카카오와 사용자의 첫 만남을 함께하는 ‘FE플랫폼팀 이야기’의 제목으로 되어있는 포스팅을 보고 시작하게된 정리
글에서 추천하는 4가지 책을 시간이 되는대로 볼 예정입니다.
- 코어 자바스크립트
-
You don’t know JS 시리즈
- Scope & Closures
- this & Object Prototypes
- Types & Grammar
- Async & Performance
- ES6 & Beyond
- 자바스크립트 완벽 가이드
- 리팩터링 2판
1차 정리
2020년 9월 7일에 시작하여 한주에 하나의 주제를 가지고 진행하는 스터디에서 정리하였습니다.
2차 정리
2023년 4월 6일부터 다시 정리 시작합니다.
2023년 4월 6일
- 데이터 타입
- 실행 컨텍스트
- this
2023년 4월 7일
- 콜백함수
- 클로저
- 프로토타입
데이터 타입
기본형과 참조형 타입이 서로 다르게 동작하는 이유를 중점으로 보자.
데이터 타입의 종류
데이터 타입에는 크게 두 가지가 있다.
- 기본형 : Number, String, Boolean, null, undefined, Symbol
- 참조형 : Object, Array, Function, Date, RegExp, Map, WeakMap, Set, WeakSet
굵게 칠해진 타입은 ES6에서 추가된 타입이다.
기본형과 참조형을 구분하는 기준은 무엇인가?
기본형은 값이 담긴 주솟값을 바로 복제하지만, 참조형은 값이 담긴 주솟값들로 이루어진 묶음을 가리키는 주솟값을 복제한다는 점이 다르다.
개발자분들이 기본형은 불변성을 띄지 않는다고 생각하는 경우도 있다. 그러나 기본형 타입은 불변성을 띈다.
데이터 타입에 관한 배경지식
- 변수 : 변할 수 있는 무언가.
- 식별자 : 어떤 데이터를 식별하는 데 사용하는 이름(변수명).
변수 선언과 데이터 할당
변수 선언
var a;
위의 코드를 해석하게 되면 변할 수 있는 데이터를 만들었다. 이 데이터의 식별자는 a로 한다.이다. 이렇게 보면 변수는 변경 가능한 데이터가 담길 수 있는 공간 또는 그릇이다.
데이터 할당
var a; // 변수 선언
a = 'abc'; // 변수 a에 데이터 할당
var a = 'abc'; // 변수 선언과 할당을 한 문장으로 표현
왜 변수 영역에 값을 직접 대입하지 않고 굳이 번거롭게 한 단계를 더 거치는 이유는? 데이터 변환으르 자유롭게 할 수 있게 함과 동시에 메모리를 더욱 효율적으로 관리하기 위한 고민의 결과이다.
변수 영역과 데이터 영역을 분리하면 중복된 데이터에 대한 처리 효율이 높아진다.
예시) 500개의 변수 공간에 동일한 값인 5를 넣을때
기본형 데이터와 참조형 데이터
불변값
변수와 상수를 구분하는 성질은 변경 가능성이다. 바꿀 수 있으면 변수, 바꿀 수 없으면 상수라는 것이다.
상수와 불변성은 같은 개념이 아니다.
변수와 상수를 구분 짓는 변경 가능성의 대상은 변수 영역 메모리다. 한 번 데이터 할당이 이루어진 변수 공간에 다른 데이터를 재할당할 수 있는지가 관건이다. 반면, 불변성 여부를 구분할 때의 변경 가능성의 대상은 데이터 영역 메모리다.
결국, 기본형 데이터인 Number, String, Boolean, null, undefined, Symbol 모두 불변값이다.
var a = 'abc';
a = a + 'def';
var b = 5;
var c = 5;
b = 7
변수 a에 문자열 abc를 할당했다가 뒤에 def를 추가하면 기존의 abc가 abcdef로 바뀌는 것이 아니라 새로운 문자열 abcdef를 만들어 그 주소를 변수 a에 저장한다.
즉 abc와 abcdef는 완전히 별개의 데이터다.
가변값
참조형 데이터는 가변값이다.
var obj1 = {
a: 1,
b: 'bbb'
};
기본형 데이터와의 차이는 객체의 변수(프로퍼티) 영역이 별도로 존재한다는 점이다.
var obj1 = {
a: 1,
b: 'bbb'
};
obj1.a = 2;
위와 같이 obj1의 a에 값을 재할당하게 되면 2가 들어갈 공간을 새로 만들어서 데이터를 넣어주고, 식별자 a 값에 새로 만든 2가 들어가 있는 공간의 주솟값을 넣게 된다. 이렇게 되면 a는 값만 바뀌는 것이다.
참조 카운트가 0이 되는 메모리 주소는 가비지 컬렉션의 수거 대상이 된다. 가비지 컬렉터는 런타임 환경에 따라 특정 시점이나 메모리 사용량이 포화 상태에 임박할 때마다 자동으로 수거 대상들을 수거한다. 수거된 메모리는 다시 새로운 값을 할당할 수 있는 빈 공간이 된다.
데이터 영역은 기본형과 동일하게 불변값이다. 그러나 변수에는 다른 값을 얼마든지 대입할 수 있다. 이 부분 때문에 흔히 참조형 데이터는 불변하지 않다(가변값이다)라고 하는 것이다.
변수 복사 비교
기본형과 참조형의 복사를 비교해보자.
var a = 10;
var b = a;
var obj1 = {
c: 10,
d: 'ddd'
}
var obj2 = obj1
먼저 a는 10이 들어가 있는 데이터 영역의 주소를 값으로 가진다. b는 이런 a를 값을 그대로 가져왔으므로 같은 값을 가지게 된다.
참조형도 같다. obj1에 들어가는 데이터 영역과 변수 영역의 주솟값을 obj1의 값으로 넣게 되고 obj2는 obj1의 값을 똑같이 가지게 된다.
여기서 중요한 건 값을 바꿀 때 일어난다.
var a = 10;
var b = a;
var obj1 = {
c: 10,
d: 'ddd'
}
var obj2 = obj1
b = 15
obj2.c = 20;
b에 새로운 값을 할당하려고 한다. 그렇다면 데이터 영역에 값이 15인 값이 있는 곳을 찾고 없다면 새로운 공간을 만들며 해당 공간의 주솟값을 b에 재할당한다.
obj2.c의 값을 재할당하게 되면 객체의 변수 영역인 c의 공간의 값을 재할당하는 일이 이루어진다. 그러나 obj2 자체의 값을 바뀌지 않는다. 이같이 되면 obj1 값과 obj2의 값은 여전히 동일하다.
console.log(a !== b) // true
console.log(obj1 === obj2) // true
'일반적으로 기본형도 결국 주솟값을 참조한다' 라고 말하지 않는다. 이는 이해하기 어려워서라고 생각된다.
객체 자체를 변경하는 경우
var a = 10;
var b = a;
var obj1 = {
c: 10,
d: 'ddd'
}
var obj2 = obj1
b = 15
obj2 = {
c: 10,
d: 'ddd'
}
obj2의 새로운 객체를 할당했다. 이렇게 하는 경우 obj1과 obj2를 비교하면 같지 않다고 나온다.
데이터 영역의 새로운 공간에 새 객체가 저장되고 그 주소를 변수 영역의 obj2에 저장하기 때문이다.
불변 객체
객체의 가변성에 따른 문제점이 있다.
var user = {
name: 'josh',
gender: 'male'
}
var changeName = function(user, newName){
var newUser = user;
newUser.name = newName;
return newUser;
}
var user2 = changeName(user, 'snyung')
if(user !== user2){
console.log('유저 정보가 변경되었습니다.')
}
console.log(user.name, user2.name); // snyung snyung
console.log(user === user2) // true
위와 같은 문제점이 발생하였다. 이름을 바꾸었지만 실제로 객체의 값은 변하지 않아서 변하지 않은 것으로 인식하며, 객체의 값도 같게 된다.
위의 코드를 해결해보자.
var user = {
name: 'josh',
gender: 'male'
}
var changeName = function(user, newName){
return {
name: newName,
gender: user.gender
};
}
var user2 = changeName(user, 'snyung')
if(user !== user2){
console.log('유저 정보가 변경되었습니다.')
}
console.log(user.name, user2.name); // josh snyung
console.log(user === user2) // false
반환값으로 새로운 객체를 만들어서 반환하도록 수정되었다. 이게 두 개의 객체의 값을 다르게 되어 정보가 바뀌었다고 인식을 하게 된다.
그러나 우리가 새로운 객체를 만들면서 변경할 필요가 없는 기존 객체의 프로퍼티를 하드코딩하고 있다. 이런식으로 작성하게 되면 정보가 많을수록 변경해야하는 정보가 늘어나게 된다. 그냥 모든 프로퍼티를 복사하는 함수를 만드는 것이 좋아 보인다.
var copyObjec = function (target){
var result = {};
for (var prop in target){
result[prop] = target[prop];
}
return result;
};
var user = {
name: 'josh',
gender: 'male'
}
var user2 = copyObjec(user)
user2.name = 'snyung'
if(user !== user2){
console.log('유저 정보가 변경되었습니다.')
}
console.log(user.name, user2.name); // josh snyung
console.log(user === user2) // false
우리가 만든 함수는 위와 같은 예제에서는 제대로 작동하고 있다. 그러나 얕은 복사만 수행한다는 점이 아쉽다.
얕은 복사와 깊은 복사
얕은 복사는 바로 아래 단계의 값만 복사하는 방법이며, 깊은 복사는 내부의 모든 값을 하나하나 찾아서 전부 복사하는 방법이다.
얕은 복사를 하게 되면 한 단계 아래의 값들은 새로 만들어지기 때문에 불변성을 보장한다. 그러나 2단계 이상으로 들어가게 되면 기존의 데이터를 그대로 참조하고 있게 된다.
var user2 = copyObject(user);
user2.urls = copyObject(user.urls);
user.urls.profile = 'http://protfolio.com';
console.log(user.urls.protfolio = user2.urls.protfolio); // false
user2.urls.blog = '';
console.log(user.urls.blog === user2.urls.blog); // false
위의 결과를 보게 되면 모든 값을 새로 만들어서 할당하였더니 값이 다 다르다고 나오게 된다. 이에 우리는 기본형 데이터일 경우에는 그대로 복사하고, 참조형 데이터는 다시 그 내부의 프로퍼티들을 복사해야 한다는 것을 알게 되었다.
var copyObjectDeep = function(target) {
var result = {};
if (typeof target === 'object' && target != null){
for (var prop in target){
result[prop] = copyObjectDeep(target[prop])
}
} else {
result = target
}
return result;
}
객체인 경우 재귀적으로 함수를 재귀적으로 호출하며, 객체가 아닌 경우 원본을 그대로 넣어주고 있다.
위와 같이 재귀적으로 호출하는 방식으로 DeepCopy를 할 수 있지만, JSON 객체로도 가능하다.
var copyObjectViaJSON = function (target){
return JSON.parse(JSON.stringify(target))
}
undefined와 null
자바스크립트에서, 없음을 나타내는 값은 두 가지가 있다.
undefined는 사용자가 명시적으로 지정할 수도 있지만, 값이 존재하지 않을 때 자바스크립트 엔진이 자동으로 부여하는 경우도 있다.
자바스크립트 엔진이 undefined를 반환하는 경우는 아래와 같이 세 가지 경우다.
- 값을 대입하지 않는 변수. 즉 데이터 영역의 메모리 주소를 지정하지 않는 식별자에 접근할 때
- 객체 내부의 존재하지 않는 프로퍼티에 접근하려고 할 때
- return 문이 없거나 호출되지 않는 함수의 실행 결과
var a;
console.log(a); // undefined
var obj = {a:1};
console.log(obj.a); // a
console.log(obj.b); // undefined
console.log(b); // Uncaught ReferenceError: b is not defined
var func = function() {};
var c = func();
console.log(c); // undefined
값을 대입하지 않는 경우에 대해 배열의 경우에는 조금 다르다.
var arr1 = [];
arr1.length = 3
console.log(arr1); // [empty × 3]
var arr2 = new Array(3); // [empty × 3]
console.log(arr2);
var arr3 = [undefined, undefined, undefined];
console.log(arr3); // (3) [undefined, undefined, undefined]
위의 결과를 보게 되면 1, 2는 같은 결과를 출력하나 undefined로 만들어서 출력한 것을 다르다는 것을 알 수 있다. 이처럼 비어있는 요소와 undefined를 할당한 요소는 출력 결과부터 다르다.
비어있는 요소는 순회와 관련된 많은 배열 메서드들의 순회 대상에서 제외된다.
var arr1 = [undefined, 1];
var arr2 = [];
arr2[1] = 1;
arr1.foreach(function(v, i) { console.log(v, i); });
arr2.foreach(function(v, i) { console.log(v, i); });
arr1.map(function (v, i) { return v+i; });
arr2.map(function (v, i) { return v+i; });
arr1.filter(function (v, i) { return !v; });
arr2.filter(function (v, i) { return !v; });
arr1.reduce(function (p, c, i) { return p + c + i;}, '');
arr2.reduce(function (p, c, i) { return p + c + i;}, '');
위의 결과가 다르게 나온다. 직접 undefined를 할당한 arr1에 대해서는 일반적으로 알고 있는 배열의 모든 요소를 순회해서 결과를 출력한다. 그러나 arr2에 대한 결과를 보면, 각 메서드들이 비어있는 요소에 대해서는 어떠한 처리도 하지 않고 건너뛰었다.
결국, 값으로써 어딘가에 할당된 undefined는 실존하는 데이터다. 그러나 자바스크립트 엔진이 반환해주는 undefined는 문자 그래도 값이 없을을 나타내는 것이다.
undefined는 할당하지 않는게 좋다. 같은 의미를 가진 null이라는 값이 있는데 굳이 undefined를 사용할 이유가 없다.
null
null은 주의해야 할 점이 있다. typeof null이 Object라는 것이다. 이는 자바스크립트 자체 버그이다. 따라서 어떤 변수의 값이 null인지 여부를 판별하기 위해서는 typeof 대신 다른 방식으로 접근해야 한다.
var n = null;
console.log(typeof n); // object
console.log(n == undefined); // true
console.log(n == null); // true
console.log(n === undefined) // false
console.log(n === null) // true
동등 연산자로 비교할 경우 null과 undefined가 서로 같다고 판단한다. 따라서 어떤 변수가 실제로 null인지 아니면 undefined인지는 동등 연산자(==)로 비교해서는 알 수 없다. 일치 연산자(===)를 써야만 정확히 판별할 수 있다.
Reference
실행 컨텍스트
모든 내용은 책을 기반으로 작성되었습니다.
실행 컨텍스트는 실행할 코드에 제공할 환경 정보들을 모아놓은 객체로 동적 언어로서의 성격을 잘 파악할 수 있는 개념이다.
자바스크립트는 어떤 실행 컨텍스트가 활성화되는 시점에 선언된 변수를 위로 끌어올리고(=호이스팅), 외부 환경 정보를 구성하고, this 값을 설정하는 등의 동작을 수행한다.
실행 컨텍스트는 자바스크립트에서 가장 중요한 핵심 개념 중 하나다. 단순하게 자바스크립트 문법을 아는 것보다 실행 컨텍스트를 이해하는 것이 자바스크립트를 이해하는데 더욱 도움된다.
동일한 환경에 있는 코드를 실행 때 필요한 환경 정보들을 모아 컨텍스트를 구성하고, 이를 콜스택에 쌓아 올렸다가 가장 위에 쌓여있는 컨텍스트와 관련있는 코드들을 실행하는 식으로 전체 코드의 환경과 순서를 보장한다.
여기서 '동일한 환경', 즉 하나의 실행 컨텍스트를 구성할 방법은 무엇이 있을까?
- 전역공간
- eval()
- 함수 실행
// ----- (1)
var a = 1;
function outer() {
function inner() {
console.log(a); // ???
var a = 3;
}
inner(); // ------ (2)
console.log(a) // ??
}
outer(); // ------ (3)
console.log(a); // ??
위의 답은 무엇일까? 또한 콜스택의 변화는 어떻게 이루어질까?

실행 컨텍스트가 활성화될 때 자바스크립트 엔진은 해당 컨텍스트에 관련된 코드를 실행하는 데 필요한 환경 정보들을 수집해서 실행 컨텍스트 객체에 저장한다. 이 객체는 자바스크립트 엔진이 활용할 목적으로 생성할 뿐 개발자가 코드를 통해 확인할 수 없다.
실행 컨텍스트에 담기는 정보
VariableEnvironment: 현재 컨텍스트 내의 식별자들에 대한 정보 + 외부 환경 정보 선언 시점의 LexicalEnvironment의 스냅샷으로, 변경사항은 반영되지 않음.LexicalEnvironment: 처음에는 VariableEnvironment와 같지만, 변경사항이 실시간으로 반영됨.ThisBinding: this 식별자가 바라봐야 할 대상 객체.
VariableEnvironment
LexicalEnvironment와 내용이 같지만 최초 실행 시의 스냅샷을 유지한다는 점이 다르다. 실행 컨텍스트를 생성할 때 VariableEnvironment에 정보를 먼저 담은 다음, 그대로 복사해서 LexicalEnvironment를 만들고, 이후에는 LexicalEnvironment를 주로 사용하게 된다.
VariableEnvironment과 LexicalEnvironment의 내부는 environmentRecord와 outerEnvironment로 구성되어 있다. 초기화 과정 중에는 사실상 완전히 동일하고 이후 코드 진행에 따라 서로 달라진다.
LexicalEnvironment
environmentRecord 호이스팅
environmentRecord에는 현재 컨텍스트와 관련된 코드의 식별자 정보들이 저장된다. 컨텍스트를 구성하는 함수에 지정된 매개변수 식별자, 선언한 함수가 있으면 그 함수 자체, var로 선언된 변수의 식별자에 해당한다.
자바스크립트는 코드가 실행되기 전임에도 불구하고 자바스크립트 엔진은 이미 해단 환경에 속한 코드의 변수명들을 모두 알고 있게 된다. 여기서 호이스팅이라는 개념이 등장한다.
호이스팅이란 끌어올리다라는 의미의 hoist에 ing를 붙여 만든 동명사로, 변수 정보를 수집하는 과정을 더욱 이해하기 쉬운 방법으로 대체한 가장의 개념이다. 실제로는 끌어올리지는 않지만, 편의상 끌어올린 것으로 간주한다.
호이스팅 규칙
environmentRecord에는 매개변수의 이름, 함수 선언, 변수명 등이 담긴다.
function a (x) {
console.log(x); // ??
var x;
console.log(x); // ??
var x = 2;
console.log(x); // ??
}
a(1)
위에서 출력이 어떻게 되는지 알아보자. 인자들과 함께 함수를 호출한 경우, arguments에 전달된 인자를 담는 것을 제외하면 다음의 코드 내부에서 변수를 선언한 것과 다른 점이 없다.
실제 엔진이 이렇게 처리하지 않는다.
function a (x) {
var x = 1;
console.log(x); // 1
var x;
console.log(x); // 1
var x = 2;
console.log(x); // 2
}
a()
위와 같은 상태에서 변수 정보를 수집하는 과정인 호이스팅을 처리하게 되면 아래와 같이 변경된다.
function a (x) {
var x;
var x;
var x;
x = 1;
console.log(x); // ???
console.log(x); // ???
x = 2;
console.log(x); // ???
}
a()
위와 같이 변경하고 실제로 코드를 돌리게 되면 결과는 1, 1, 2가 나오게 된다.
함수 선언을 추가해서 예제를 보자
function a () {
console.log(b); // ???
var b = 'bbb';
console.log(b); // ???
function b () { }
console.log(b); // ???
}
a();
a 함수를 실행하는 순간 a 함수의 실행 컨텍스트가 생성된다. 이때 변수명과 함수 선언의 정보를 위로 끌어올린다.
변수는 선언부와 할당부를 나누어 선언부만 끌어올리지만 함수 선언은 함수 전체를 끌어올린다.
function a () {
var b; // 변수는 선언부만 끌어올린다.
function b () { }; // 함수 선언은 전체를 끌어올린다.
console.log(b); // ???
b = 'bbb';
console.log(b); // ???
console.log(b); // ???
}
a();
호이스팅이 끝난 상태에서의 함수 선언문은 함수명으로 선언한 변수에 함수를 할당한 것처럼 여길 수 있다.
function a () {
var b; // 변수는 선언부만 끌어올린다.
var b = function b () { }; // 함수 선언은 전체를 끌어올린다.
console.log(b); // ???
b = 'bbb';
console.log(b); // ???
console.log(b); // ???
}
a();
만약 호이스팅의 개념을 알고 있지 않다면, 에러 / 'bbb' / 'b'함수라고 생각했을 것이다. 그러나 우리는 이제 호이스팅으로 답이 'b'함수 / 'bbb' / 'bbb'라는 것을 알 수 있게 되었다.
함수 선언문과 함수 표현식
함수를 정의하는 방법은 두 가지가 있다. 함수 선언문, 함수 표현식이다.
함수 선언문은 function 정의부만 존재하고 별도의 할당 명령이 없는 것을 의미한다. 함수 표현식은 정의한 function을 별도의 변수에 할당하는 것을 말한다.
함수 선언문의 경우 반드시 함수명이 정의돼 있어야 하지만, 함수 표현식은 없어도 된다.
function a () {}
var b = function () { }
var c = function d() { }
한때 디버깅할때 익명 함수표현식보다 기명 함수표현식이 좋을때가 있었다.
이제 예제를 통해서 함수 선언문과 함수 표현식의 실질적인 차이를 살펴보자.
console.log(sum(1,2)); // ???
console.log(multiply(3,4)); // ???
function sum (a, b) {
return a + b;
}
var multiply = function (a, b) {
return a * b;
}
실행 컨텍스트의 LexicalEnvironment는 두 가지 정보를 수집한다. 여기서는 environmentRecord의 정보 수집 과정에서 발생하는 호이스팅이다.
이제 호이스팅이 되었을 경우 어떻게 표현이 가능한지 살펴보자.
var sum = function () {
return a + b;
}
var multiply;
console.log(sum(1,2));
console.log(multiply(1,2));
multiply = function (a, b) {
return a * b;
}
함수 선언문은 전체를 호이스팅한다. 그러나 함수 표현식은 변수 선언부만 호이스팅했다. 함수도 하나의 값으로 취급할 수 있다는 것이 바로 이런 것이다. 함수를 다른 변수에 값으로써 '할당'한 것이 곧 함수 표현식이다.
함수 선언문의 위험성
console.log(sum(3,4));
function sum (x, y) {
return x + y;
}
var a = sum(1, 2);
function sum (x, y){
return x + ' + ' + y + ' = ' + (x + y);
}
var c = sum(1, 2);
console.log(c);
이렇게 실행했다면 우리는 호이스팅이라는 개념을 알기 때문에 하위에 선언한 함수가 적용되어 값이 출력된다는 것을 예측할 수 있다.
그러나 실제로 위에서 선언한 함수를 인지하지 못하고 하위에서 다시 sum을 선언해서 개발하는 경우가 생긴다. 그렇게 되면 자바스크립트는 실행 컨텍스트를 만드는 과정에서 호이스팅이 발생하는 것을 인지하지 못하고 개발하여 이전에 개발된 것까지 버그가 발생하게 된다.
이렇게 되면 정말 최악의 경우 모든 기능이 마비될 수 있다.
그러나 이를 함수 표현식으로 정의했다면 원래의 의도대로 동작하게 되면서, 디버깅도 손쉽게 되었을 것이다.
스코프, 스코프 체인, outerEnvironmentReference
스코프란 식별자에 대한 유효범위다. 어떤 경계 A의 외부에서 선언한 변수의 A의 외부뿐 아니라 A의 내부에서도 접근이 가능하지만, A의 내부에서 선언한 변수는 오직 A의 내부에서만 접근할 수 있다.
ES5까지의 자바스크립트는 전역공간을 제외하면 오직 함수에 의해서만 스코프가 생성된다. '식별자의 유효범위'를 안에서부터 바깥으로 차례로 검색해나가는 것을 스코프 체인이라고 한다. 그리고 이를 가능하게 하는 것이 LexicalEncironment의 두 번재 수집 자료인 outerEnvironmentReference다.
스코프 체인
outerEnvironmentReference는 현재 호출된 함수가 선언될 당시의 LexicalEnvironment를 참조한다.
여러 스코프에서 동일한 식별자를 선언한 경우에는 무조건 스코프 체인 상에서 가장 먼저 발견된 식별자에만 접근 가능하다.
var a = 1;
var outer = function () {
var inner = function () {
console.log(a) // ???
var a = 3;
}
inner();
console.log(a); // ???
}
outer();
console.log(a); // ???

스코프 체인 상에 있는 변수라고 해서 무조건 접근 가능한 것은 아니다. a를 전역과 inner 내부에 선언했는데 inner 함수 내부에서 a에 접근하려고 하려고 하면 무조건 스코프 체인 상의 첫 번째 인자인 LexicalEnvironment부터 검색할 수밖에 없다. inner 스코프의 LexicalEnvironment에 a 식별자가 존재하므로 스코프 체인 검색을 더 진행하지 않고 inner 함수의 a를 반환한다. 이를 이용해서 사용하는 기술이 변수 은닉화다.
전역변수와 지역변수
- 전역변수 : 전역 공간에 선언한 변수.
- 지역변수 : 함수 내부에서 선언한 변수.
우리가 여태 보았던 것처럼 함수를 선언하는 방법은 여러 가지지만 표현식으로 선언하는 것과 가급적 전역변수 사용을 최소화하고자 노력하는 것이 안정성을 위해서 좋다.
정리
실행 컨텍스트는 실행할 코드에 제공할 환경 정보들을 모아놓은 객체이다. 실행 컨텍스트는 전역 공간에서 자동으로 생성되는 전역 컨텍스트와 eval 및 함수 실행에 의한 컨텍스트가 있다.
실행 컨텍스트가 활성화되는 시점에 VariableEnvironment, LexicalEnvironment, ThisBiding의 세 가지 정보를 수집한다.
실행 컨텍스트를 생성할 때는 VariableEnvironment와 LexicalEnvironment가 동일한 내용으로 구성되지만 LexicalEnvironment는 함수 실행 도중에 변경되는 사항이 즉시 반영된다.
LexicalEnvironment는 매개변수, 변수의 식별자, 선언한 함수의 함수명 등을 수집하는 environmentRecord와 바로 직전 컨텍스트의 LexicalEnvironment 정보를 참조하는 outerEnvironment로 구성되어 있다.
호이스팅
호이스팅은 코드 해석을 좀 더 수월하게 하기 위해 environmentRecord의 수집 과정을 추상화한 개념이다. 실행 컨텍스트가 관여하는 코드 집단의 최상단으로 이들을 '끌어올린다'고 해석하는 것이다.
변수 선언과 값 할당이 동시에 이뤄진 문장은 '선언부'만을 호이스팅하고, 할당 과정은 원래 자리에 남아있게 되는데, 여기서 함수선언문과 함수표현식의 차이가 발생한다.
스코프
스코프는 변수의 유효범위를 말한다. outerEnvironmentReference는 해당 함수가 선언된 위치의 LexicalEnvironment를 참조한다. 코드 상에서 어떤 변수에 접근하려고 하면 현재 컨텍스트의 LexicalEnvironment를 탐색해서 발견되면 그 값을 반환하고, 발견하지 못할 경우 다시 outerEnvironment에 담긴 LexicalEnvironment를 탐색하는 과정을 거친다. 전역 컨텍스트까지 가서 찾지 못하면 undefined를 반환한다.
전역 컨텍스트의 LexicalEnvironment에 담긴 변수를 전역변수라 하고, 그 밖의 함수에 의해 생성된 실행 컨텍스트의 변수들은 모두 지역변수이다. 안전한 코드 구성을 위해 가급적 전역변수의 사용은 최소화하는 것이 좋다.
this
모든 내용은 책을 기반으로 작성되었습니다.
다른 대부분의 객체지향 언어에서 this는 클래스로 생성한 인스턴스 객체를 의미한다. 그러나 자바스크립트에서의 this는 어디서든 사용할 수 있다. 상황에 따라 this가 바라보는 대상이 달라진다.
상황에 따라 달라지는 this
this는 우리가 앞에서 선행한 실행컨텍스트 안에 있는 정보 중 하나이다. 이를 토대로 우리가 알 수 있는 것은 this도 실행컨테스트와 함께 지정된다는 것을 알 수 있다.
실제로 실행컨텍스트가 생성될 때 함께 결정된다.
실행컨텍스트는 함수가 호출될 때 생성되므로, this도 함수가 호출될 때 결정된다. 함수를 어떤 방식으로 호출하느냐에 따라 값이 달라진다.
전역공간에서의 this
전역 공간에서 this는 전역 객체이다. 전역 컨텍스트를 생성하는 주체는 전역 객체이기 때문에 이는 당연하다고 생각한다.
전역 변수를 선언하면 자바스크립트 엔진은 이를 전역 객체의 프로퍼티로 할당한다(전역 컨텍스트의 Lexical Environment는 전역 객체 그대로 참조.)
자바스크립트에서 window의 프로퍼티로 변수를 만드는 것과 var로 변수를 생성하는 경우에 있어 delete의 작동이 다른 것을 알 수 있다. 이는 사용자가 의도치 않게 삭제하는 것을 방지하는 차원에서 마련한 나름의 방어 전략이라고 한다.(configurable 속성의 차이)
메서드로서 호출할 때 메서드 내부에서의 this
함수를 실행하는 방법은 여러가지가 있다. 그중 가장 일반적인 방법은 함수로서 호출하는 경우와 메서드로서 호출하는 경우이다.
이 둘을 구분하는 유일한 차이는 독립성이다.
함수는 그 자체로 독립적인 기능을 수행하나, 메서드는 자신을 호출한 대상 객체에 관한 동작을 수행한다. 자바스크립트는 상황별로 this 키워드에 다른 값을 부여하게 함으로써 이를 구현했다.
흔히 자바스크립트에서 메서드를 객체의 프롶퍼티에 할당된 함수로 이해한다. 이는 반만 맞은 것인데, 할당한다고 해서 무조건 메서드가 되는 것이 아니라 객체의 메서드로 호출이 될 경우 비로소 메서드로 동작하는 것이 그렇지 않는 것은 함수로 동작하는 것이다.
그렇다면 "함수로서 호출"과 "메서드로서 호출"을 어떻게 구분할까? 바로 함수 앞에 점(.)이 있는지 여부만으로 간단하게 구분할 수 있다(진짜로).
점 표기법이든 대괄호 표기법이든 어떤 함수를 호출할 때 그 함수 이름(프로퍼티명) 앞에 객체가 명시돼 있는 경우에는 메서드로 호출한 것이며, 그렇지 않은 것은 함수로 호출한 것이다.
매서드 내부에서의 this
this에는 호출한 주체에 대한 정보가 담긴다. 어떤 함수를 메서드로서 호출하는 경우 호출 주체는 바로 함수명(프로퍼티명) 앞의 객체이다. 점 표기법의 경우 마지막 점 앞에 명시된 객체가 곧 this가 되는 것이다.
함수 내부에서의 this
어떤 함수를 함수로서 호출할 경우에는 this가 지정되지 않는다. 2장에서 실행 컨텍스트를 활성화할 당시에 this가 지정되지 않는 경우 this는 전역객체를 바라본다고 했다. 따라서 함수에서의 this는 전역객체이다.
더글라스 크락포드는 이를 명백한 설계상의 오류라고 지적합니다.
메서드의 내부함수에서의 this
결국 함수를 실행하는 당시의 주변 환경(메서드 내부인지, 함수내부인지 등)은 중요하지 않고, 오직 해당 함수를 호출하는 구문 앞에 점 또는 대괄호 표기가 있는지 없는지가 관건이다.
메서드의 내부 함수에서의 this를 우회하는 방법
대표적인 방법으로 변수를 활용하는 방법이다.
var obj = {
outer: function() {
console.log(this); // ??
var innerFunc1 = function () {
console.log(this); // ??
}
innertFunc1();
var self = this;
var innerFunc2 = function () {
console.log(self); // ??
}
innerFunc2();
}
}
obj.outer();
답: (1) obj1, (2) 전역객체(window), (3) obj2
결국 this 바인딩에 관해서는 함수를 실행하는 당시의 주변 환경(메서드 내부인지, 함수 내부인지 등)은 중요하지 않고, 오직 해당 함수를 호출하는 구문 앞에 점 또는 대괄호 표기가 있는지 없는지가 관건인 것이다.
이를 해결하기 위해서 self라는 변수를 outer 내부에 만들고 this를 할당하는 방식으로 해결했다(또는 _).
this를 바인딩하지 않는 함수
ES6에서는 함수 내부에서 this가 전역객체를 바라보는 문제를 보완하고자, this를 바인딩하지 않는 화살표 함수를 새로 도입했다. 화살표 함수는 실행컨텍스트를 생성할 때 this 바인딩 과정 자체가 빠지게 되어, 상위 스코프의 this를 그대로 활용할 수 있다. 내부 함수를 화살표 함수로 바꾸면 우회법이 불필요해진다.
그러나 ES5에서는 사용할 수 없다.
콜백 함수 호출 시 그 함수 내부에서의 this
setTimeout(function () {
console.log(this); // ??
}, 300);
[1, 2, 3, 4, 5].forEach(function (x) {
console.log(x); // ??
})
document.body.innerHTML += '<button id="a">클릭</button>';
document.body.querySelector('#a').addEventListener('click', function (a) {
console.log(this, a); // ??
})
답 (1) 전역객체(Window), (2) 전역객체(Window), (3) 버튼 엘리먼트
특별히 정의하지 않는 경우에는 기본적으로 함수와 마찬가지로 전역객체를 바라본다.
생성자 함수 내부에서의 this
생성자 함수는 어떤 공통된 성질을 지니는 객체들을 생성하는 데 사용하는 함수이다.
자바스크립트는 함수에 생성자로서의 역할을 함께 부여했다.
new 명령어와 함께 함수를 호출하면 해당 함수가 생성자로서 동작하게 된다.
그리고 어떤 함수가 생성자 함수로서 호출된 경우 내부에서의 this는 인스턴스 자신이 된다.
var Cat = function (name, age) {
this.bark = '야옹';
this.name = name;
this.age = age;
}
var choco = new Cat('초코', 7);
var nabi = new Cat('나비', 5);
console.log(choco, nabi);
명시적으로 this를 바인딩하는 방법
this에 특정 대상을 바인딩하는 방법이 있다.
call 메서드
Function.prototype.call(thisarg [, arg1[, arg2[, ...]]])
call 메서드는 호출 주체인 함수를 즉시 실행하는 명령이다. 이때 call의 첫 번째 인자를 this로 바인딩하고, 이후의 인자값을 함수의 매개변수로 한다.
apply 메서드
Function.prototype.apply(thisarg [, argsArray])
apply 메서드는 call 메서드와 기능적으로 완전히 동일하다. call 메서드는 첫 번째 인자를 제외한 나머지 모든 인자들을 호출할 함수의 매개변수로 지정하는 반면, apply 메서드는 두 번째 인자를 배열로 받아 매개변수로 지정한다는 차이가 있다.
bind 메서드
Function.prototype.bind(thisarg [, arg1[, arg2[, ...]]])
bind 메서드는 ES5에 추가된 기능으로, call과 비슷하지만 즉시 호출하지는 않고 넘겨받은 this 및 인수들을 바탕으로 새로운 함수를 반환하는 메서드이다.
name 프로퍼티
bind 메서드를 적용해서 새로 만든 함수는 독특한 성질이 있다. 바로 name 프로퍼티에 'bound'라는 접두어가 붙는다는 것이다.
bind된 함수는 다시 bind를 할 수 없다.
화살표 함수의 예외 사항
ES6에 새롭게 도입된 화살표 함수는 실행 컨텍스트 생성 시 this를 바인딩하는 과정이 제외됐다. 즉 이 함수 내부에는 this가 아예 없으며, 접근하고자 하면 스코프체인상 가장 가까운 this에 접근하게 된다.
정리
- 명시적으로 this를 바인딩 하지 않는다면 아래의 규칙을 따른다.
- 전역공간에서 this는 전역객체(브라우저는 window, Node에서는 global)
- 어떤 함수를 메서드로 호출한 경우, this는 메서드 호출 주체
- 어떤 함수를 함수로 호출한 경우, this는 전역
- 콜백 함수 내부에서의 this는 해당 콜백 함수의 제어권을 넘겨받은 함수가 정의한 바에 따르며, 정의되지 않는 경우 전역
- 생성자 함수에서 this는 생성된 인스턴스
- 명시적으로 바인딩 하는 방법
- call, apply 메서드는 this를 명시적으로 지정하며, 함수 또는 메서드를 호출한다.
- bind 메서드는 this 및 함수에 넘길 인수를 지정해서 함수를 만든다.
- 요소를 순회하면서 콜백 함수를 반복 호출하는 내용의 일부 메서드는 별도의 인자로 this를 받을 수 있다.
콜백 함수
모든 내용은 책을 기반으로 작성되었습니다.
콜백 함수는 다른 코드의 인자로 넘겨주는 함수다. 콜백 함수를 넘겨받은 코드는 콜백 함수를 필요에 따라 적절한 시점에 실행할 것이다.
콜백 함수는 제어권과 관련이 깊다.
콜백 함수는 다른 코드(함수 또는 메서드)에게 인자로 넘겨줌으로써 그 제어권도 함께 위임한 함수다.
콜백 함수를 위임받은 코드는 자체적으로 내부 로직에 의해 콜백 함수를 적절한 시점에 실행할 것이다.
이전 글에서 '콜백함수도 함수이기 때문에 기존적으로는 this가 전역객체를 참조하지만, 제어권을 넘겨받은 코드에서 콜백 함수에 별도로 this가 될 대상을 지정한 경우에는 그 대상을 참조하게 된다'고 했다.
제어권
호출 시점
var count = 0;
var cdFunc = function () {
console.log(count);
if(++count > 4) clearInterval(timer);
}
var timer = setInterval(cdFunc, 300)
이처럼 콜백 함수의 제어권을 넘겨받은 코드는 콜백 함수 호출 시점에 대한 제어권을 가진다.
인자
map 메서드를 호출해서 원하는 배열을 얻으려면 map 메서드에 정의된 규칙에 따라 함수를 작성해야한다.
콜백 함수를 호출하는 주체가 사용자가 아닌 map 메서드이므로 map 메서드가 콜백 함수를 호출할 때 인자에 어떤 순서로 넘길 것인지가 전적으로 map 메서드에게 달렸다.
this
this에 다른 값이 담기는 이유를 정확히 알 수 있다. 바로 제어권을 넘겨받을 코드에서 call/apply 메서드의 첫 번째 이자에 콜백 함수 내부에서의 this가 될 대상을 명시적으로 바인딩하기 때문이다.
setTimeout(function () { console.log(this) }, 300); // window
[1,2,3,4,5].forEach(function (x) {
console.log(this)
}) // window
document.body.innerHTML += '<button id="a">클릭</button>';
document.body.querySelectore('#a').addEventListener('click', function () {
console.log(this, e); // <button id="a">클릭</button>, MouseEvent
});
각각 콜백 함수 내에서의 this를 살펴보면, 우선 첫 번째 setTimeout은 내부에서 콜백 함수를 호출할 때 call 메서드의 첫 번째 인자에 전역객체를 넘기기 때문에 콜백 함수 내부에서의 this가 전역객체를 가리킨다. 두 번째 forEach는 별도의 인자로 this를 받는 경우에 해당하지만 별도의 인자로 this를 넘겨주지 않았기 때문에 전역객체를 가리키게 된다. 세 번째 addEventListener는 내부에서 콜백 함수를 호출할 때 call 메서드의 첫 번째 인자에 addEventListener 메서드의 this를 그대로 넘기도록 정의돼 있기 때문에 콜백 함수 내부에서의 this가 addEventListener를 호출한 주체인 HTML 엘리먼트를 가리키게 된다.
콜백 함수는 함수다.
콜백 함수로 어떤 객체의 메서드를 전달하더라도 그 메서드는 메서드가 아닌 함수로서 호출된다.
콜백 함수 내부의 this에 다른 값 바인딩하기
객체의 메서드를 콜백 함수로 전달하면 해당 객체를 this로 바라볼 수 없게 된다는 것은 위에서 알게 되었다. 그럼에도 콜백 함수 내부에서 this가 객체를 바라보게 하고 싶으면 어떻게 해야할까? 별도의 인자로 this를 받는 함수의 경우에는 여기에 원하는 값을 넘겨주면 되지만, 그렇지 않은 경우에는 this의 제어권도 넘겨주게 되므로 사용자가 임의로 값을 바꿀 수 없다.
그래서 전통적으로는 this를 다른 변수에 담아 콜백 함수로 활용할 함수에서는 this 대신 그 변수를 사용하게 하고, 이에 클로저로 만드는 방식이 많이 사용되었다.
다행히 이제는 전통적인 방식의 아쉬움을 보완하는 방법으로 bind 메서드가 있다.
콜백 지옥과 비동기 제어
콜백 지옥은 콜백 함수를 기명함수로 전달하는 과정이 반복되어 코드의 들여쓰기 수준이 감당하기 힘들 정도로 깊어지는 현상으로, 자바스크립트에서 흔히 발생하는 문제이다. 주로 이벤트 처리나 서버 통신과 같이 비동기적인 작업을 수행하기 위해 이런 형태가 자주 등장하곤 하는데, 가독성이 떨어질뿐더러 코드를 수정하기도 어렵다.
동기적인 코드는 현재 실행중인 코드가 완료된 후에야 다음 코드를 실행하는 방식이다. 반대로 비동기적인 코드는 현재 실행 중인 코드의 완료 여부와 무관하게 즉시 다음 코드로 넘어간다. CPU의 계산에 의해 즉시 처리가 가능한 대부분의 코드는 동기적인 코드이다.
계산식이 복잡해서 CPU가 계산하는 데 시간이 많이 필요한 경우라 하더라도 이는 동기적인 코드다. 반면 사용자의 요청에 의해 특정 시간이 경과되기 전까지 어떤 함수의 실행을 보류한다거나 사용자의 직접적인 개입이 있을 때 비로소 어떤 함수를 실행하도록 대기한다거나, 웨브라우저 자체가 아닌 별도의 대상에 무언가를 요청하고 그에 대한 응답이 왔을 때 비로소 어떤 함수를 실행하도록 대기하는 등, 별도의 요청, 실행 대기, 보류 등과 관련된 코드는 비동적인 코드이다.
현대의 자바스크립트는 웹의 복잡도가 높아진 만큼 비동기적인 코드의 비중이 예전보다 훨씬 높아진 상황이다. 그와 동시에 콜백 지옥에 빠지기도 훨씬 쉬어진 셈이다.
콜백 지옥 예시를 보자.
setTimeout(function (name) {
var coffeeList = name;
console.log(coffeeList);
setTimeout(function (name){
coffeeList += ', ' + name;
console.log(coffeeList);
setTimeout(function (name){
coffeeList += ', ' + name;
console.log(coffeeList);
}, 500, '카페라떼');
}, 500, '카페모카');
}, 500, '아메리카노')
가독성 문제와 어색함을 동시에 해경하는 가장 간단한 방법은 익명의 콜백 함수를 모두 기명함수로 전환하는 것이다.
var coffeeList = '';
var addEspresso = function (name) {
coffeeList = name;
console.log(coffeeList);
setTimeout(addAmericano, 500, '아메리카노')
}
var addAmericano = function (name) {
coffeeList += ', ' + name;
console.log(coffeeList);
setTimeout(addMocha, 500, '카페모카')
}
var addMocha = function (name) {
coffeeList += ', ' + name;
console.log(coffeeList);
setTimeout(addLatte, 500, '카페라떼')
}
var addLatte = function (name) {
coffeeList += ', ' + name;
console.log(coffeeList);
}
ES6에서는 Promise, Generator 등이 도입됐고, ES2017에서는 async/await가 도입되었다. 이들을 이용해 위코드를 수정한 내용을 각각 간략하게 알아보자.
new Promise(function (resolve) {
setTimeout(function () {
var name = '에스프레소';
console.log(name);
resolve(name)
}, 500)
}).then(function(prevName){
return new Promise(function (resolve) {
setTimeout(function () {
var name = prevName + ', 아메리카노';
console.log(name);
resolve(name)
}, 500)
})
}).then(function(prevName){
return new Promise(function (resolve) {
setTimeout(function () {
var name = prevName + ', 카페모카';
console.log(name);
resolve(name)
}, 500)
})
}).then(function(prevName){
return new Promise(function (resolve) {
setTimeout(function () {
var name = prevName + ', 카페라떼';
console.log(name);
resolve(name)
}, 500)
})
})
한편 ES2017에서는 가독성이 뛰어나면서 작성법도 간단한 새로운 기능이 추가됐는데, 바로 async/await이다. 비동기 작업을 수행하고자 하는 함수 앞에 async를 표기하고, 함수 내부에서 실질적인 비동기 작업이 필요한 위치마다 await를 쵸기하는 것만으로 뒤의 내용을 Promise로 자동 전환하고, 해당 내용이 resolve된 이유에야 다음으로 진행한다. 즉 Promise의 then과 흡사한 효과를 얻을 수 있다.
정리
- 콜백 함수는 다른 코드에 인자로 넘겨줌으로써 그 제어권도 함께 위임한 함수다.
- 제어권을 넘겨받은 코드는 다음과 같은 제어권을 가진다.
- 콜백 함수를 호추하는 시점을 스스로 판단해서 실행한다.
- 콜백 함수를 호출할 때 인자로 넘겨줄 값들 및 그 순서가 정해져 있다. 이 순서를 따르지 않고 코드를 작성하면 이상한 결과가 나온다.
- 콜백 함수의 this가 무엇을 바라보도록 할지가 정해져 있는 경우도 있다. 정하지 않은 경우에는 전역객체를 바라본다. 사용자 임의로 this를 바꾸고 싶은 경우 bind 메서드를 사용하면 된다.
- 어떤 함수에 인자로 메서드를 전달하더라도 이는 결국 함수로서 실행한다(this가 전역이라는 걸 알려주려고 하는 듯)
- 비동기 제어를 위해 콜백 함수를 사용하다 보면 콜백 지옥에 빠지기 쉽다. 최근의 ECMAScript에는 Promise, Generator, async/await 등 콜백 지옥에서 벗어날 수 있는 훌륭한 방법들이 있다.
Closure(클로저)
모든 내용은 책을 기반으로 작성되었습니다.
클로저라는 개념은 여러 함수형 프로그래밍 언어에서 등장하는 보편적인 특성이다. 자바스크립트 고유의 개념이 아니라서 ECMAScript 명세에서도 클로저의 정의 다루지 않고 있다.
다양한 서적에서 클로저를 한 문장으로 요약해서 설명하는 부분들을 소개하면 아래와 같다.
- 자신을 내포하는 함수의 컨텍스트에 접근할 수 있는 함수
- 함수가 특정 스코프에 접근할 수 있도록 의도적으로 그 스코프에서 정의하는 것
- 함수를 선언할 때 만들어지는 유효범위가 사라진 후에도 호출할 수 있는 함수
- 이미 생명 주기상 끝난 외부 함수의 변수를 참조하는 함수
- 자유 변수가 있는 함수와 자유 변수를 알 수 있는 환경의 결합
- 로컬 변수를 참조하고 있는 함수 내의 함수
- 자신이 생성될 때의 스코프에서 알 수 있었던 변수들 중 언젠가 자신이 실행될 때 사용할 변수들만을 기억하여 유지하는 함수
MDN은 클로저에 대해서 "클로저는 함수와 그 함수가 선언될 당시의 Lexical Environment의 상호관계에 따른 현상"이라고 적혀있다.
'선언될 당시의 Lexical Environment'는 이전에 2장에서 소개한 실행 컨테스트의 구성 요소 중 하나인 outerEnvironmentReferences에 해당한다.
위에서의 의미만 조합해 본다면, '어떤 함수에서 선언한 변수를 참조하는 내부함수에서만 발생하는 현상`이라고 볼 수 있다.
var outer = function() {
var a = 1;
var inner = function () {
console.log(++a);
};
inner()
}
outer();
위의 예제에서 outer함수에서 변수 a를 선언했고, outer의 내부함수인 inner에서 a의 값을 1만큼 증가시킨 다음 출력한다.
inner 함수 내부에서는 a를 선언하지 않아서 environmenRecord에서 값을 찾지 못하므로 outerEnvironmentReference에 지정된 상위 컨텍스트인 outer의 outerEnvironment에 접근해서 다시 a를 찾는다.
outer 함수의 실행 컨텍스트가 종료되면 Lexical Environment에 저장된 식별자들에 대한 참조를 지운다. 그렇게 되면 자신을 참조하는 변수가 하나도 없게 되므로 가비지 컬렉터의 수집대상이 된다.
var outer = function() {
var a = 1;
var inner = function () {
console.log(++a);
};
return inner; // 여기가 바뀜
}
var outer2 = outer();
console.log(outer2()); // 2
console.log(outer2()); // 3
이번에는 inner 함수를 반환했다.
그러면 outer함수의 실행 컨텍스트가 종료될 때 outer2 변수는 outer의 실행 결과인 innter 함수를 참조하게 된다. 이후 outer2를 함수로 호출하게 되면 inner가 실행되게 된다.
inner 함수의 실행 컨텍스트의 environmentRecord에는 수집할 정보가 없다. outerEnvironmentReference에는 innter 함수가 선언된 위치의 Lexical Environment가 참조 복사된다. inner 함수는 outer 함수 내부에서 선언되었으므로, outer 함수의 Lexical Environment가 담기게 된다. 이제 스코프체이닝에 따라 outer에서 선언한 변수 a에 접근해서 1만큼 증가시킨 후 결과를 찍는다.
그런데 inner함수의 실행 시점에는 outer함수는 이미 실행이 종료된 상태인데 outer함수의 LexicalEnvrionment에 어떻게 접근할 수 있을까?
이는 가비지 컬렉터의 동작 방식 때문이다. 가비지 컬렉터는 어떤 값을 참조하는 변수가 하나라도 있다면 그 값은 수집 대상에 포함되지 않는다.
위와 같은 이유론 inner함수가 a에 접근이 가능한 것이다.
이때까지 내용을 보게 되면 클로저는 어떤 함수 A에서 선언한 변수 a를 참조하는 내부함수 B를 외부로 전달할 경우 A의 실행 컨텍스트가 종료된 이후에도 변수 a가 사라지지 않는 현상이다.
return 없이도 클로저가 발생하는 다양한 경우
(function () {
var a = 0;
var intervalId = null;
var inner = function () {
if (+=a >= 10){
clearInterval(inervaId);
}
console.log(a);
}
intervalId = setInterval(inner, 1000);
})()
(function () {
var count = 0;
var button = document.createElement('button');
button.innerText = 'click';
button.addEventListener('click', function() {
console.log(++count, 'times clicked');
})
document.body.appendChild(button)
})()
첫 번째는 별도의 외부 객체인 window의 메서드(setTimeout 또는 setInterval)에 전달할 콜백 함수 내부에서 지역변수를 참조한다.
두 번째는 별도의 외부 객체인 DOM의 메서드(addEventListener)에 등록할 handler 함수 내부에서 지역변수를 참조한다.
두 경우 모두 지역변수를 참조하는 내부함수를 외부에 전달했기 때문에 클로저다.
클로저와 메모리 관리
메모리 누수의 위험 이유로 클로저 사용을 조심해야 한다거나 심지어 지양해야 한다고 주장하는 사람들도 있지만, 메모리 소모는 클로저의 본질적인 특성일 뿐이다.
오히려 이러한 특성을 정확히 이해하고 잘 활용하도록 노력해야 한다.
관리 방법은 간단하다. 클로저는 어떤 필요 때문에 의도적으로 함수의 지역변수를 메모리를 소모하도록 함으로써 발생한다. 그렇다면 그 필요성이 사라진 시점에는 더는 메모리를 소모하지 않게 해주면 된다.
식별자에 참조형이 아닌 기본형 데이터(보통 null이나 undefined)를 할당하면 된다.
var outer = (function () {
var a = a;
var inner = function () {
return ++a;
}
return inner;
})();
console.log(outer());
console.log(outer());
outer = null
(function () {
var a = 0;
var intervalId = null;
var inner = function() {
if(++a >= 10){
clearInterval(intervalId);
inner = null;
}
console.log(a);
};
intervalId = setInterval(inner, 1000);
})();
(function () {
var count = 0;
var button = document.createElement('button');
button.innerText = 'click';
var clickHandler = function(){
console.log(++count, 'times clicked')
if(count >= 10){
button.removeEventListener('click', clickHandler);
clickHandler = null;
}
};
button.addEventListener('click', clickHandler);
document.body.appendChild(button);
})();
클로저 활용 사례
콜백 함수 내부에서 외부 데이터를 사용하고자 할 때
var fruits = ['apple', 'banana', 'peach'];
var $ul = document.createElement('ul'); // (공통 코드)
fruits.forEach(function(fruit) {
// (A)
var $li = document.createElement('li');
$li.innerText = fruit;
$li.addEventListener('click', function() {
// (B)
alert('your choice is ' + fruit);
});
$ul.appendChild($li);
});
document.body.appendChild($ul);
위의 예제에서 B 함수의 쓰임새가 콜백함수에 국한되지 않는 경우라면 반복을 줄이기 위해서 외부로 분리하는 편이 좋다.
var fruits = ['apple', 'banana', 'peach'];
var $ul = document.createElement('ul');
var alertFruit = function(fruit) {
alert('your choice is ' + fruit);
};
fruits.forEach(function(fruit) {
var $li = document.createElement('li');
$li.innerText = fruit;
$li.addEventListener('click', alertFruit);
$ul.appendChild($li);
});
document.body.appendChild($ul);
alertFruit(fruits[1]);
공통함수로 쓰고자 콜백함수를 외부로 꺼내서 alertFruit 변수에 담았다. 이제 함수를 직접 실행할 수 있다. 그런데 각 li를 클릭하면 클릭한 대상의 과일명이 아닌[object MouseEvent]라는 값이 출력된다. 콜백 함수의 인자에 대한 제어권을 addEvnetListener가 가진 상태이며, addEventListener는 콜백 함수를 호출할 때 첫 번째 인자에 '이벤트 객체'를 주입하기 때문이다. 이를 bind로 해결할 수 있다.
var fruits = ['apple', 'banana', 'peach'];
var $ul = document.createElement('ul');
var alertFruit = function(fruit) {
alert('your choice is ' + fruit);
};
fruits.forEach(function(fruit) {
var $li = document.createElement('li');
$li.innerText = fruit;
$li.addEventListener('click', alertFruit.bind(null, fruit));
$ul.appendChild($li);
});
document.body.appendChild($ul);
이렇게 하면 이벤트 객체가 인자로 넘어오는 순서가 바뀌는 점과 함수 내부에서의 this가 원래의 값과 달라지는 점을 감안해야한다. 이를 해결하기 위햇 다른방식으로 고차함수를 활용하는 것이다. 함수형 프로그래밍에서 자주 쓰이는 방식이다.
var fruits = ['apple', 'banana', 'peach'];
var $ul = document.createElement('ul');
var alertFruitBuilder = function(fruit) {
return function() {
alert('your choice is ' + fruit);
};
};
fruits.forEach(function(fruit) {
var $li = document.createElement('li');
$li.innerText = fruit;
$li.addEventListener('click', alertFruitBuilder(fruit));
$ul.appendChild($li);
});
document.body.appendChild($ul);
alertFruitBuilder라는 함수를 만들었다.
이 함수는 내부에서 익명함수를 반환하는데, 이 익명함수가 바로 기존의 alertFruit 함수다. alertFruitBuilder함수를 실행하면서 fruit값을 인자로 전달하고, 그러면 이 함수의 실행 결과가 다시 함수가 되며, 이렇게 반환된 함수를 리스너에 콜백 함수로써 전달할 것이다.
접근 권한 제어(정보 은닉)
정보 은닉이란 어떤 모듈의 내부 로직에 대해 외부로의 노출을 최소화해서 모듈 간의 결합도를 낮추고 유연성을 높이고자 하는 현대 프로그래밍 언어의 중요한 개념 중 하나이다.
자바스크립트는 기본적으로 변수 자체에 이러한 접근 권한을 직접 부여하도록 설계되어 있지 않다. 그렇다고 접근 권한 제어가 불가능한 건 아니다. 클로저를 이용하면 된다.
var car = {
fuel: Math.ceil(Math.random() * 10 + 10), // 연료(L)
power: Math.ceil(Math.random() * 3 + 2), // 연비(km/L)
moved: 0, // 총 이동거리
run: function() {
var km = Math.ceil(Math.random() * 6);
var wasteFuel = km / this.power;
if (this.fuel < wasteFuel) {
console.log('이동불가');
return;
}
this.fuel -= wasteFuel;
this.moved += km;
console.log(km + 'km 이동 (총 ' + this.moved + 'km)');
},
};
이렇게 하면 run 메서드만 호출한다는 가정하에는 충분하다. 그러나 자바스크립트는 값을 변경할 수 있다.
car.fuel = 10000;
car.power = 100;
car.moved = 1000;
아래와 같이 바꾸지 못하도록 클로저로 방어가 가능하다. 필요한 멤버만 return 하는 것이다.
var createCar = function() {
var fuel = Math.ceil(Math.random() * 10 + 10); // 연료(L)
var power = Math.ceil(Math.random() * 3 + 2); // 연비(km / L)
var moved = 0; // 총 이동거리
return {
get moved() {
return moved;
},
run: function() {
var km = Math.ceil(Math.random() * 6);
var wasteFuel = km / power;
if (fuel < wasteFuel) {
console.log('이동불가');
return;
}
fuel -= wasteFuel;
moved += km;
console.log(km + 'km 이동 (총 ' + moved + 'km). 남은 연료: ' + fuel);
},
};
};
var car = createCar();
위와 같이 바꾸게 될 경우 run 메서드를 다른 내용으로 덮어씌우는 어뷰징은 여전히 가능하지만, 이전의 코드보다는 안전한 코드가 되었다.
어뷰징까지 막기 위해서는 객체를 return하기 전에 미리 변경할 수 없게 조치를 하면 된다.
var createCar = function() {
var fuel = Math.ceil(Math.random() * 10 + 10); // 연료(L)
var power = Math.ceil(Math.random() * 3 + 2); // 연비(km / L)
var moved = 0; // 총 이동거리
var publicMembers = {
get moved() {
return moved;
},
run: function() {
var km = Math.ceil(Math.random() * 6);
var wasteFuel = km / power;
if (fuel < wasteFuel) {
console.log('이동불가');
return;
}
fuel -= wasteFuel;
moved += km;
console.log(km + 'km 이동 (총 ' + moved + 'km). 남은 연료: ' + fuel);
},
};
Object.freeze(publicMembers); // 추가
return publicMembers;
};
var car = createCar();
부분 적용 함수
부분 적용 함수란 n개의 인자를 받는 함수에 미리 m개의 인자만 넘겨 기억시켰다가, 나중에 (n-m) 개의 인자를 넘기면 비로소 원래 함수의 실행 결과를 얻을 수 있게하는 함수다. this를 바인딩해야 하는 점을 제외하면 앞서 살펴본 bind 메서드의 실행 결과가 바로 부분 적용 함수다.
var add = function() {
var result = 0;
for (var i = 0; i < arguments.length; i++) {
result += arguments[i];
}
return result;
};
var addPartial = add.bind(null, 1, 2, 3, 4, 5);
console.log(addPartial(6, 7, 8, 9, 10)); // 55
앞서 말했던 내용과 동일하게 this를 변경할 수밖에 없기 때문에 메서드에서는 사용할 수 없다. this에 관여하지 않는 별도의 부분 적용 함수를 만들어 보자.
var partial = function() {
var originalPartialArgs = arguments;
var func = originalPartialArgs[0];
if (typeof func !== 'function') {
throw new Error('첫 번째 인자가 함수가 아닙니다.');
}
return function() {
var partialArgs = Array.prototype.slice.call(originalPartialArgs, 1);
var restArgs = Array.prototype.slice.call(arguments);
return func.apply(this, partialArgs.concat(restArgs));
};
};
var add = function() {
var result = 0;
for (var i = 0; i < arguments.length; i++) {
result += arguments[i];
}
return result;
};
var addPartial = partial(add, 1, 2, 3, 4, 5);
console.log(addPartial(6, 7, 8, 9, 10)); // 55
var dog = {
name: '강아지',
greet: partial(function(prefix, suffix) {
return prefix + this.name + suffix;
}, '왈왈, '),
};
dog.greet('입니다!'); // 왈왈, 강아지입니다.`
보통의 경우 부분 적용 함수는 이 정도로 충분하다.
다른 예제로 많이 사용하는 디바운스를 구현해보자. 디바운스는 짧은 시간 동안 동일한 이벤트가 많이 발생할 겨웅 이를 전부 처리하지 않고 처음 또는 마지막에 발생한 이벤트에 대해 한 번만 처리하는 것으로 최적화에 큰 도움을 주는 기능 중 하나이다.
var debounce = function(eventName, func, wait) {
var timeoutId = null;
return function(event) {
var self = this;
console.log(eventName, 'event 발생');
clearTimeout(timeoutId);
timeoutId = setTimeout(func.bind(self, event), wait);
};
};
var moveHandler = function(e) {
console.log('move event 처리');
};
var wheelHandler = function(e) {
console.log('wheel event 처리');
};
document.body.addEventListener('mousemove', debounce('move', moveHandler, 500));
document.body.addEventListener(
'mousewheel',
debounce('wheel', wheelHandler, 700)
);
커링 함수
커링 함수란 여러 개의 인자를 받는 함수를 한의 인자만 받는 함수로 나눠서 순차적으로 호출될 수 있게 체인 형태로 구성한 것을 말한다.
커링은 한 번에 하나의 인자만 전달하는 것을 원칙으로 한다. 또한, 중간 과정상의 함수를 실행한 결과는 그다음 인자를 받기 위해 대기만 할 뿐으로 마지막 인자가 전달되기 전까지는 원본 함수가 실행되지 않는다.
var curry3 = function(func) {
return function(a) {
return function(b) {
return func(a, b);
};
};
};
var getMaxWith10 = curry3(Math.max)(10);
console.log(getMaxWith10(8)); // 10
console.log(getMaxWith10(25)); // 25
var getMinWith10 = curry3(Math.min)(10);
console.log(getMinWith10(8)); // 8
console.log(getMinWith10(25)); // 10
커링함수는 당장 필요한 정보만 받아서 전달하고 또 필요한 정보가 들어오면 전달하는 식으로 하면 결국 마지막 인자가 넘어갈 때까지 함수 실행을 미루는 셈이다. 이를 함수형 프로그래밍에서는 지연실행이라고 칭한다. 원하는 시점까지 지연시켰다가 실행하는 것이 용이한 상황이라면 커링을 쓰기에 적합하다.
최근 여러 프레임워크나 라이브러리 등에서 커링을 상당히 광범위하게 사용하고 있다.
Flux 아키텍처의 구현체 중 하나인 Redux의 미들웨어를 예로 들면 logger와 thunk 둘 다 공통적으로 store, next, action 순서로 인자를 받는다. 이 중 store는 프로젝트 내에서 한 번 생성된 이후로는 바뀌지 않는 속성이고, dispatch의 의미를 가지는 next 역시 마찬가지이다. action의 경우 매번 달라진다.
결국, store와 next값이 결정되면 Redux 내부에서 logger 또는 thunk에 store, next를 미리 넘겨서 반환된 함수를 저장시켜놓고, 이후에는 action만 받아서 처리할 수 있게 한 것이다.
정리
클로저란 어떤 함수에서 선언한 변수를 참조하는 내부함수를 외부로 전달할 경우, 함수의 실행컨텍스트가 종료된 후에도 해당 변수가 사라지지 않는 현상.
내부함수를 외부로 전달하는 방법에는 함수를 return하는 경우만 아니라 콜백으로 전달하는 경우도 포함이다.
클로저는 그 본질이 메모리를 계속 차지하는 개념으로 더이상 사용하지 않게 된 클로저에 대해서는 메모리를 관리해주어야한다.
프로토타입
모든 내용은 책을 기반으로 작성되었습니다.
자바스크립트는 프로토타입기반 언어이다.
클래스 기반 언어에서는 '상속'을 사용하지만, 프로토타입 기반 언어에서는 어떤 객체를 원형으로 삼고 이를 복제(참조)함으로써 상속과 비슷한 효과를 얻는다.
프로토타입의 개념 이해
constructor, prototype, instance
var instance = new Constructor();
- 어떤 생성자 함수를 new 연산자와 함께 호출하면
- Constructor에서 정의된 내용을 바탕으로 새로운 인스턴스가 생성된다.
- 이때 instance에는 __proto__라는 프로퍼티가 자동으로 부여된다.
- 이 프로퍼티는 Constructor의 prototype이라는 프로퍼티를 참조한다.
prototype이라는 프로퍼티와 __proto__라는 프로퍼티가 새로 등장했는데, 이 둘의 관계가 프로토타입 개념의 핵심이다.
var Person = function(name){
this._name = name;
}
Person.prototype.getName = function () {
return this._name;
}
이제 Person의 인스턴스는 proto 프로퍼티를 통해 getName을 호출 할 수 있다.
var suzi = new Person('Suzi');
suzi.__proto__.getName(); //undefined
Person.prototype === suzi.__proto__ // true
메서드 호출 결과로 undefined가 나온 점에 주목해 보면, Suzi라는 값이 안나오지도 했지만 에러가 나지 않았다는 것이다.
이를 통해서 this 바인딩이 잘못됐다는 것을 알 수 있었고, this가 suzi.__proto__가 된 것이다.
__proto__는 생략 가능한 프로퍼티이기 때문에 생략해서 사용하면 정상적으로 나온다.
프로토타입의 개념을 좀 더 상세히 설명하면, 자바스크립트는 함수에 지동으로 객체인 prototype 프로퍼티를 생성해 놓는ㄴ데, 해당 하마수를 생성자 함수로서 사용할 경우, 즉 new 연산자와 함께 호출할 경우, 그로부터 생성된 인스턴스에는 숨겨진 프로퍼티 __proto__가 자동으로 생성되며, 이 프로퍼티는 생성자 함수의 prototype 프로퍼티를 참조한다.
proto 프로퍼티는 생략 가능하도록 구현돼 있기 때문에 생성자 함수의 prototype에 어떤 메서드나 프로퍼티가 있다면 인스턴스에서도 마치 자신의 것처럼 메서드나 프로퍼티에 접근할 수 있게 된다.
constructor 프로퍼티
생성자 함수의 프롶퍼티인 prototype 객체 내부에는 constructor라는 프로퍼티가 있다.
인스턴스로부터 그 원형이 무엇인지를 알 수 있는 수단이기도 하다.
var arr = [1,2];
Array.prototype.constructor === Array // true
arr.__proto__.constructor === Array // true
arr.constructor === Array // true
contructor를 변경하더라도 참조하는 대상이 변경될 뿐 이미 만들어진 인스턴스의 원형이 바뀐다거나 데이터 타입이 변하는 것은 아니다.
어떤 인스턴스의 생성자 정보를 알아내기 위해 constructor 프로퍼티에 의존하는 건 안전하지 않다.
프로토타입 체인
prototype 객체를 참조하는 __proto__를 생략하면 인스턴스는 prototype에 정의된 프로퍼티나 메서드를 마치 자신의 것처럼 사용할 수 있다.
만약 인스턴스가 동일한 이름의 프로퍼티나 메서드를 가지고 있는 상황이라면 어떻게 될까?
var Person = function (hane) {
this.name = name;
}
Person.prototype.getName = function () {
return this.name;
}
var iu = new Person('지금');
iu.getName = function () {
return '바로 ' + this.name;
};
console.log(iu.getName()); // 바로 지금
이러한 현상을 메서드 오버라이드라고 한다.
메서드 위에 메서드를 덮어씌웠다는 표현으로 원본을 제거하고 다른 대상으로 교체하는 것이 아니라 원본이 그대로 있는 상태에서 다른 대상을 얹는다고 생각하면 된다.
prototype 객체는 '객체'이다. 기본적으로 모든 객체의 __proto__에는 Object.prototype이 연결된다. prototype 객체도 예외가 아니다.
어떤 데이터의 proto 프로퍼티 내부에 다시 proto 프로퍼티가 연쇄적으로 이어진 것을 프로토타입 체인이라 하고, 이 체인을 따라가며 검색하는 것을 프로토타입 체이닝이라고 한다.
객체 전용 메서드의 예외사항
어떤 생성자 함수이든 prototype은 반드시 객체이기 때문에 Object.prototype이 언제나 프로토타입 체인의 최상단에 존재하게 된다.
프로토타입 체인상 가장 마지막에는 언제나 Object.prototype이 있다고 했는데, 예외적으로 Object.create를 이용하면 Object.prototype의 메서드에 접근할 수 없는 경우가 있다. 즉 __proto__가 없는 것이다.
다중 프로토타입 체인
자바스크립트의 기본 내장 데이터 타입들은 모두 프로토타입 체인이 1단계(객체)이거나 2단계(나머지)로 끝나는 경우만 있었지만 사용자가 새롭게 만드는 경우에는 그 이상도 가능하다.
이 방법으로 클래스와 비슷하게 동작하는 구조를 만들 수 있다.
정리
어떤 생성자 함수를 new 연산자와 함께 호출하면 constructor에서 정의된 내용을 바탕으로 새로운 인스턴스가 생성되는데, 이 인스턴스에는__proto__라는, Constructor의 prototype 프로퍼티를 참조하는 프로퍼티가 자동으로 부여된다.
__proto__는 생략 가능한 속성이라서, 인스턴스는 Constrictor. prototype의 메서드를 자신의 메서드인 것처럼 호출할 수 있다.
Constructor.prototype에는 constructor라는 프로퍼티가 있는데, 이는 다시 생성자 함수 자신을 가리킵니다. 이 프로퍼티는 인스턴스가 자신의 생성자 함수가 무엇인지를 알고자 할 때 필요한 수단입니다.
직각삼각형의 대각선 방향. 즉 proto 방향을 계속 찾아가면 최종적으로는 Object.prototype에 당도하게 된다. 이런 식으로 proto 안에 다시 __proto__를 찾아가는 과정을 프로토타입 체이닝이라고 하며, 이 프로토타입 체이닝을 통해 각 프로토타입 메서드를 자신의 것처럼 호출할 수 있습니다. 이때 접근 방식은 자신으로부터 가장 가까운 대상에서 먼 대상으로 나아가며, 원하는 값을 찾으면 검색을 중단한다.
Object.prototype에는 모든 데이터 타입에서 사용할 수 있는 범용적인 메서드만이 존재하며, 객체 전용 메서드는 여느 데이터 타입과 달리 Object 생성자 함수에 스태틱하게 담겨있다. 프로토타입 체인은 반드시 2단계로만 이뤄지는 것이 아니라 무한대의 단계를 생성할 수도 있다.
클래스
모든 내용은 책을 기반으로 작성되었습니다.
자바스크립트는 프로토타입 기반 언어라서 '상속'개념이 존재하지 않는다.
클래스와 비슷하게 동작하게 흉내 내는 여러 기법들이 탄생했으며 이들 중 몇 가지는 널리 알려졌다.
ES6의 클래스에서도 일정 부분은 프로포타입을 활용하고 있다.
클래스와 인스턴스의 개념 이해
어떤 클래스의 속성을 지니는 실존하는 개체를 일컬어 인스턴스(instance)라고 한다.
프로그래밍 언어에서의 클래스는 현실세계에서의 클래스와 마찬가지로 '공통요소를 지니는 집단을 분류하기 위한 개념'이라는 측면에서는 일치하지만 인스턴스들로부터 공통점을 발견해서 클래스를 정의하는 현실과 달리, 클래스가 먼저 정의돼야만 그로부터 공통적인 요소를 지니는 개체들을 생성할 수 있다.
나아가 현실세계에서의 클래스는 추상적인 개념이지만, 프로그래밍 언어에서의 클래스는 사용하기에 따라 추상적인 대상일 수도 있고 구체적인 개체가 될 수도 있다.
자바스크립트의 클래스
프로토타입을 일반적인 의미에서의 클래스 관점에서 접근해보면 비슷하게 해석할 수 있는 요소가 없지 않다.
생성자 함수 Array를 new 연산자와 함께 호출하면 인스턴스가 생성된다. 이때 Array를 일종의 클래스라고 하면, Array의 prototype 객체 내부 요소들이 인스턴스에 '상속'된다고 볼 수 있다(엄밀히 말하면 프로토타입 체이닝).
인스턴스에 상속되는지(인스턴스가 참조하는지) 여부에 따라 **스태틱 멤버(static member)**와 **인스턴스 멤버(instance member)**로 나뉜다.
인스턴스 메서드라는 명칭은 프로토타입 메서드(prototype method)라고 부는 편이 좋다.
프로토타입 객체에 할당한 메서드는 인스턴스가 자신의 것처럼 호출할 수 있다고 했다. 이처럼 인스턴스에서 직접 호출할 수 있는 메서드가 바로 프로토타입 메서드다.
스택틱 메서드는 생성자 함수를 this로 해야만 호출할 수 있다.
ex) Rectangle.isRectangle(rect1) // static method
구체적인 인스턴스가 사용할 메서드를 정의한 '틀'의 역할을 담당하는 목적을 가질 때의 클래스는 추상적인 개념이지만, 클래스 자체를 this로 해서 직접 접근해야만 하는 스태틱 메서드를 호출할 때의 클래스는 그 자체가 하나의 개체로서 취급된다.
클래스 상속
ES5까지의 자바스크립트에는 클래스가 없습니다. ES6에서 클래스가 도입됐지만 역시나 prototype을 기반으로 한 것이다. 자바스크립트에서 클래스 상속을 구현했다는 것은 결국 프로토타입 체이닝을 잘 연결한 것으로 이해하면 된다.
[예제 7-3 / 예제 7-4]
클래스에 있는 값이 인스턴스의 동작에 영향을 줘서는 안된다. 사실 이런 형향을 줄 수 있다는 사실 자체가 이미 클래스의 추상성을 해치는 것이다. 인스턴스와의 관계에서는 구체적인 데이터를 지니지 않고 오직 인스턴스가 사용할 메서드만을 지니는 추상적인 '틀'로서만 작용하게끈 작성하지 않는다면 예기치 않은 오류가 발생할 가능성을 안고 가야한다.
하위 클래스로 삼을 생성자 함수의 prototype에 상위 클래스의 인스턴스를 부여하는 것만으로도 기본적인 메서드 상속은 가능하지만 다양한 문제가 발생할 여지가 있어 구조적 안정성이 떨어진다.
클래스가 구체적인 데이터를 지니지 않게 하는 방법
가장 쉬운 방법은 일단 만들고 나서 프로퍼티들을 일일이 지우고 도는 새로운 프로퍼티를 추가할 수 없게 하는 것이다.
다른 방법으로는 더글라스 크락포드가 제시해서 대중적으로 널리 알려진 방법으로, SubClass의 prototype에 직접 SuperClass의 인스턴스를 할당하는 대신 아무런 프로퍼티를 생성하지 않은 빈 생성자(Bridge)를 하나 더 만들어서 그 prototype이 SuperClass의 Prototype을 바라보게 한 다음, SubClass의 prototype에는 Bridge의 인스턴스를 할당하게 하는 것이다.
이렇게 하면 인스턴스를 제외한 프로토타입 체인 경로상에는 더는 구체적인 데이터가 남아있지 않게 된다.
마지막으로, ES5에서 도입된 Object.create를 이용한 방법이다.
이 방법은 SubClass의 prototype의 __proto__가 SuperClass의 prototype을 바라보되, SuperClass의 인스턴스가 되지 않으므로 위의 두 방법보다 간단하면서 안전하다.
constructor 복구하기
위 모든 방법은 상속에는 성공했지만 SubClass 인스턴스의 constructor는 여전히 SuperClass를 가리티는 상태다. 엄밀히는 SubClass 인스턴스에는 constructor가 없고, SubClass.prototype에도 없다.
프로토타입 체인상에 가장 먼저 등장하는 SuperClass.prototype의 constructor에서 가리티는 대상, 즉 SuperClass가 출력될 뿐이다.
결국 SubClass.prototype.constructor가 원래의 SubClass를 바라보도록 해주면 된다.
상위 클래스에의 접근 수단 제공
하위 클래스의 메서드에서 상위 클래스의 메서드 실행 결과를 바탕으로 추가적인 작업을 수행하고 싶을 때가 있다.
여기서 만든 방법은 SuperClass의 생성자 함수에 접근하고자 할 때는 this.super(), SuperClass의 프로토타입 메서드에 접근하고자 할 때는 this.super(propName)와 같이 사용하면 된다.
ES6의 클래스 및 클래스 상속
ES6에서는 본격적인 클래스 문법이 도입되었다.
정리
자바스크립트는 프로토타입 기반 언어라서 클래스 및 상속 개념은 존재하지 않지만 프로토타입을 기반으로 클래스와 비슷하게 동작하게끔 하는 다양한 기법들이 도입되어왔다.
클래스는 어떤 사물의 공통 속성을 모아 정의한 추상적인 개념이고, 인스턴스는 클래스의 속성을 지니는 구체적인 사례다. 상위 클래스(superclass)의 조건을 충족하면서 더욱 구체적인 조건이 추가된 것을 하위 클래스(subclass)라고 한다.
클래스의 prototype 내부에 정의된 메서드를 프로토타입 메서드라고 하며, 이들은 인스턴 스가 마치 자신의 것처럼 호출할 수 있다. 한편 클래스(생성자 함수)에 직접 정의한 메서드를 스태틱 메서드라고 하며, 이들은 인스턴스가 직접 호출할 수 없고 클래스(생성자 함수)에 의해서만 호출할 수 있다.
클래스 상속을 흉내내기 위해 세 가지 방법을 소개했다.
바로 SubClass.prototype에 SuperCLass의 인스턴스를 할당한 다음 프로퍼티를 모두 삭제하는 방법, 빈 함수(Bridge)를 활용하는 방법, Object.create를 이용하는 방법이다.
이 세 방법 모두 constructor 프로 퍼티가 원래아 생성자 함수를 바라보도록 조정해야 한다. 추가로 샹위 클래스에 접근할 수 있는 수단인 super를 구현해봤다.
여기까지 상속 및 추상화를 구현하기 위해 상당히 복잡한 방법을 사용했는데, ES6에서는 상당히 간단하게 처리되는 것을 확인했다.